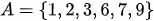This page contains notes, errata corrige, and additional information for my technical books. Almost all the errata and typos have been integrated into the second edition of the books.
Machine Learning Algorithms (First edition)
Page 25:
The correct number of misclassified samples in the figure is 3, 14, and 24, respectively.
Page 59:
The transformation matrix W for the PCA must be transposed:
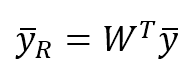
Page 97:
As explained in the previous chapters, normalizing the dataset is almost always a good practice. In this way, it becomes zero-centered, and in the linear expression, it’s possible to avoid the use of bias. Otherwise, it’s necessary to rewrite the expression as:
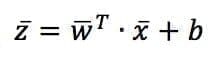
Both w and b are parameters to learn.
Page 100:
The left part of the cross-entropy formula is wrong because its arguments are the two distributions. The right one is:
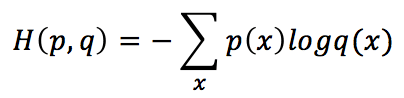
Page 103:
Addendum: In the “stochastic” gradient descent, the batch size is often set equal to 1. It means that a weight update is performed after every sample is presented. However, there are many papers and books where the attribute “stochastic” is referred to every mini-batch size.
Page 219:
The dendrogram must be cust at a threshold slightly below 30.
Pages 238 and 268:
The singular value decomposition is intended without the computation of full matrices and therefore it’s limited to the t principal singular values and vectors. The correct formula is:
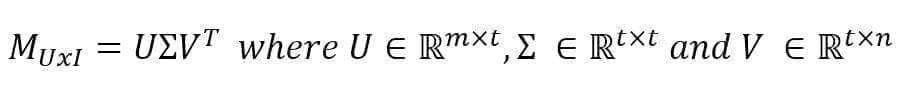
Mastering Machine Learning Algorithms (First edition)
Page 32:
The formula at the end of the page is based on argmin, as this is a minimization:
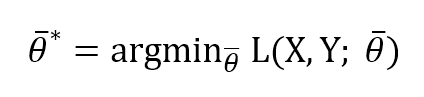
Page 92:
The code snippet containing the loop for the label propagation is:
while np.linalg.norm(Yt - Y_prev, ord=1) > tolerance: P = np.dot(D_rbf_inv, W_rbf) Y_prev = Yt.copy() Yt = np.dot(P, Yt) Yt[0:nb_samples - nb_unlabeled] = Y[0:nb_samples - nb_unlabeled]
Mastering Machine Learning Algorithms (Second edition)
Page 9:
The set in the first row is: