

Nowadays, the smallest online store has many more products than the largest physical store. Moreover, the number of websites selling products is increasing, even if the largest companies continue trying to establish monopolies in almost any country. If we add all the B2C services that provide specific information (e.g., hotels, movies, bars, and so on), the number of possibilities becomes extremely high.
Imagine having dozens of T-shirts. They are all clean and ready to use. You wake up in the morning and need to pick one of them. According to a merely statistical view, the uncertainty is proportional to the number of possible choices, and the real-life isn’t so different. However, if you have, for example, 100 T-shirts and write your everyday choices in a notebook, you can plot a histogram after one year. Count the number of times you picked a T-shirt (not utterly random because we seldom make random decisions) and draw a bar proportional to this number. What kind of shape do you expect?
Probably many people have answered: “A flat line,” like the one shown in the following figure:
It’s possible, but unfortunately, the shape will be different in most cases. Your attraction for each differs even if you bought all the 100 T-shirts. Moreover, when a decision is unconstrained (e.g., the T-shirt is dirty), you will select according to an almost unconscious priority-management system. Such a schema (considering its nature, we can call it Linus’ blanket bias) doesn’t represent an exclusive scenario: it happens everywhere and in many different situations. The result is shown in the next diagram, where the peak represents a favorite color, brand, or simply the most adaptable choice (i.e., we can save time):
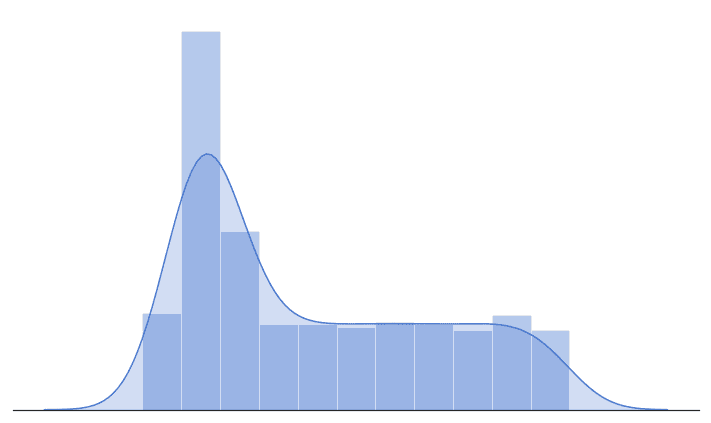
At this point, we can try to define “recommendation.” Starting from the assumption that most choices are biased, we can try to determine two important factors. The first one is the attraction point. In other words, we can recommend employing analogies. This is a 98%-sure strategy for acceptance because everybody desires (consciously or unconsciously) to hear what he/she already thinks. However, the conversion rate can be low because the options around this point are extensive. In other words, the recommendation is not rejected but seldom considered for an “investment.”
The other factor is the discovery desire. I assume that everybody, to a certain extent, desires to discover new things, but unfortunately, we don’t know the objects or the search direction. For example, I like blue T-shirts, but I have seen a new pattern that attracts me too. In this case, the two elements are the specific item I saw and the pattern. The first one is like the centroid of a cluster, and I’m very likely to buy it. The second one (previously called direction) is the set of elements belonging to this cluster. Generally, a recommendation of any item belonging to the cluster (in particular, if it’s close to the centroid) will be positively accepted, or, in the worst case, it will be used to start an exploration. In both cases, the conversion rate is generally higher.
Hence, recommendations are essential only when they can change a mental schema. This is not an absolute statement, but during my experiences, I’ve often received positive confirmations. Conversely, many new machine-learning approaches are focused on these ideas. They are moving from a classic “similarity-based” approach to a more complex schema where an unsupervised approach is employed with a reinforcement learning one. It can seem weird, but the most straightforward strategy to improve a recommendation is asking the user to evaluate the suggestions. This is true, not because the users are always perfectly aware of their desires but because a more extensive set of possibilities can be efficiently pruned using the feedback.
Moreover, adding some “noise” is generally helpful if a good recommendation should be a discovery. Suppose this scenario: a user visits a website where he often buys products. He’s on the subway and has some time to spare, so he starts checking a few products on the home page. He searches for something specific (don’t be surprised if he finds the same items seen in the morning because repeating a few actions is a typical interaction pattern). Then, he may see a product that didn’t catch his attention. Many tools (like heat maps or clickstream analyzers) can be employed to gather all the necessary information; however, let’s suppose that we know that he read the description, scrolled up and down many times, and zoomed in on the pictures.
What kind of information can we obtain from this session? First, the product and its features are relevant for that customer (even if he has never bought a similar product). Moreover, we can determine some behavioral patterns that are often considered useless. For example, what are the pictures that attracted his attention? How long did he look at a zoomed picture? Let’s suppose that the item is a backpack. Did he look at the lateral profile? Probably, he’s interested in large or narrow backpacks. So, now we have a new centroid for a bunch of recommendations. How can we use the feedback? In this case, we restrict the set by understanding whether he’s interested in large or narrow backpacks. We can pick and show a few representative elements during the next visit.
What is the user going to do? There are many possible questions; the answers can improve or worsen the recommendations. If the user clicks only on the narrow backpack, a reinforcement learning approach will increase the expected reward of a sequence of actions (in this case, they can be simply products, supposing that the user is an agent that has to make a single decision), driving the model in the direction where the user is probably looking. It doesn’t matter if he continues to buy the same items: whenever such behavioral patterns are present and analyzed, recommendations will be closer to the concept of discovery, and the additional conversion rate (we assume not to alter some established behaviors) will be proportionally higher. This is not magic, but statistical analysis of social and psychological contexts, and, yes, human beings are much more predictable than expected!
This is, for instance, the case of books. If you like thrillers, you’re probably going to buy them. But if you are attracted by a recipe book (as discussed before), a good series of suggestions can increase the probability that you will add a recipe book to your typical list of items.
Hence, we can summarize the main elements of a successful system:
-
- Recommendations must be discoveries, and discoveries cannot confirm what a user already knows.
- Interaction behavioral patterns can be used to understand a user’s hidden (or latent) interest.
- Feedback can help in refining the suggestions.
- Exploiting the refined pattern can dramatically increase the probability of conversion for uncommon items.
- Standard (or classical) recommendation strategies can also be employed as a first or a secondary approach.
- An online store or a B2C service aims not to limit access to the products/items but to spread them. Hence, a little bit of noise can increase the discovery factor and help the customers to make up their minds (strange but true, because, in case the user can pick a new item, in the opposite, he can decide to pursue his initial search strategy as the alternative are inadequate)
Therefore, my answer is: “Yes! Recommendations are essential… unless they don’t try to reinvent the wheel (in a customer’s mind)!”
(Also published on Medium)
If you like this post, you can always donate to support my activity! One coffee is enough!