
Recommendations and Feedbacks

Personal data are becoming harder to retrieve, and the latest regulations (i.e., GDPR) allow users to interact with a service without data collection. Moreover, a reliable personal profile must be built using many often hidden attributes and can only be inferred using predictive models. Conversely, implicit feedbacks are easy to collect but incredibly scarce. Strategies based on the factorization of the user-item matrix [3] are easy to implement (considering the possibility of employing parallelized algorithms). Still, the discrepancy between the number of ratings and products is usually too high to allow an accurate estimation.
Our experience showed that it’s possible to create very accurate user profiles (also for anonymous users identified only by a random ID) by exploiting the implicit feedback in textual reviews. Our main assumption is that reviews classified as spam reflect a user’s wishes concerning a specific experience. In other words, a simple sentence like “The place was very noisy” implies that I prefer quiet places or, adding extra constraints, that, in a specific situation (characterized by n factors), a quiet place is preferable to a noisy one. Our approach is based on this hypothesis and can be adapted to cope with many different scenarios.
Assumptions
We assume that a user is represented as a real-valued feature vector of fixed length Nu:
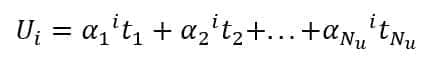
Each topic ti is represented by a label corresponding to a set of semantically coherent words, for example:

Standard topic modeling approaches (like LDA [1]) can be employed to discover the topics defined in a large set (corpus) of reviews. However, this strategy can lead to a large amount of incoherent results. The main reasons are:
-
- LDA works with vectorizations based on frequencies or TF-IDF therefore, the words are not considered in their semantic context
- One fundamental assumption is that each topic is characterized by a small set of words which are peculiar to it
While the latter can be easily managed, the former is extremely problematic. Reviews are not homogenous documents that can be trivially categorized (e.g., politics, sports, economics, and so forth). On the contrary, they are often made up of the same subset of words that can acquire different meanings thanks to the relative context.
This problem can be solved with different Deep-Learning solutions (like Word2Vec [5], GloVe [6], or FastText [7]), but we have focused on Word2Vec with a Skip-Gram model.
The main idea is to train a deep neural network to find the best vectorial representation of a word considering the context where it’s placed in all the documents. The generic structure of the network is shown in the following figure:
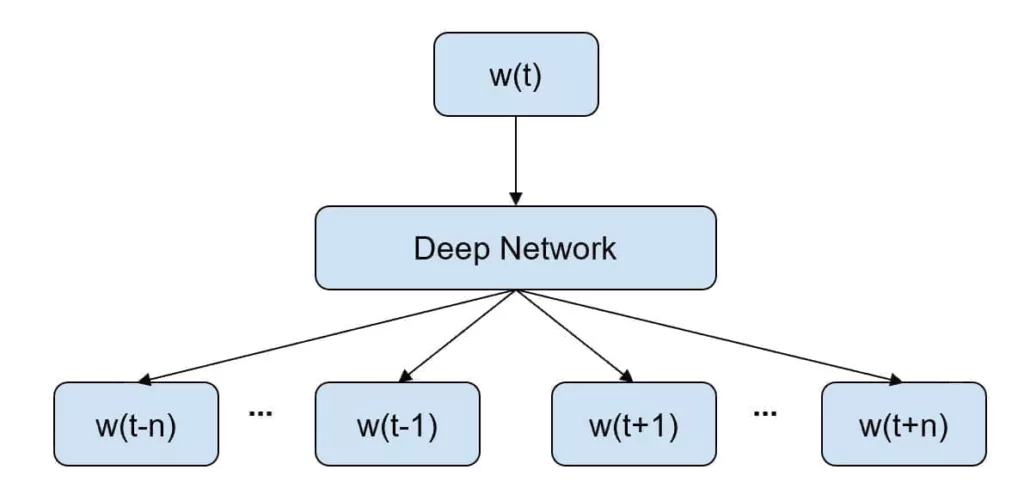
Each review is split into sub-reviews of 2n words around a pivot we feed as input. The goal of the training process is to force the network to rebuild the context given the pivot. As the vectors are rather long (100-300 32 bit float values), the process will converge to a global solution where semantically similar words are placed into very dense balls whose radius is quite smaller than the whole dictionary sub-space.
Hence, for example, the word “room” will be implicitly a synonym of “chamber” and the cosine distance between the two vectors will be extremely small. As many people use jargon terms in their reviews (together with smileys or other special characters), this approach guarantees the robustness needed to evaluate the content without undesired biases.
For further technical details, I suggest reading [5], however, the general dynamic is normally based on a random initialization of the vectors and a training process where the output layer is made up of softmax units representing the probability of each word. As this approach is unfeasible considering the number of words, techniques like Hierarchical Softmax or Negative Contrastive Estimations are employed as cost functions. In general, after a few iterations (10 – 50), the global representation is coherent with the underlying semantic structure.
Our model
To create the recommender, we selected 500,000 reviews written in English and employed Gensim [9] to create the vectorial representation after basic NLP preprocessing (in particular, stop-words and punctuation removal). The vector size has been chosen to be 256 to optimize the GPU support in the following stages.
As explained before, standard LDA cannot be applied with word vectors, but Das et al. proposed a solution [2] that allows the modeling of the topics as multivariate Gaussian distributions. As the authors observed, this choice offers an optimal solution for real-valued representations that can be compared using the Euclidean distance. An example is shown in the following figure:
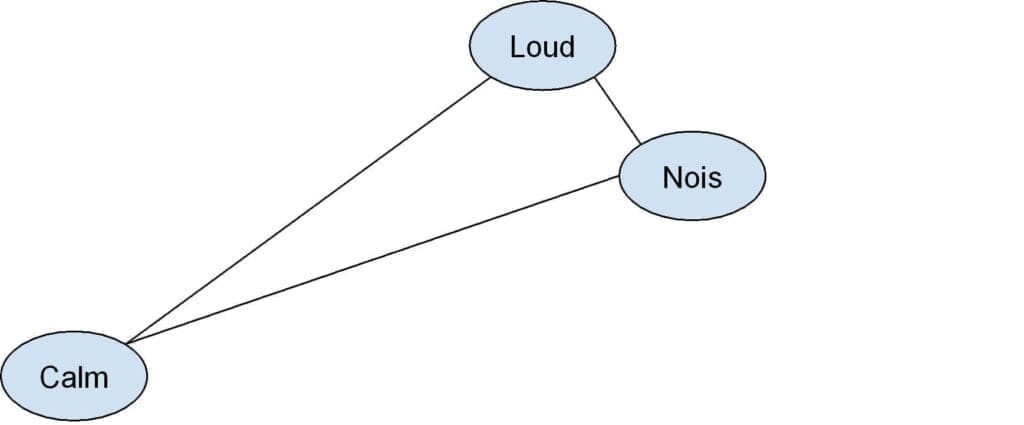
What we observe at the end of the training is:

This is an obvious consequence of the triangle inequality, but it’s extremely useful when working with implicit feedback; we can avoid being worried about misunderstood synonyms unless they are in incoherent contexts. However, this possibility is rare, assuming the reviews are prefiltered to avoid spam.
Gaussian LDA requires the specification of a desired number of topics. In our project, we started with 100 topics, and after a few evaluations, we reduced the number to 10. An example of 3 topics (in the context of Berlin hotel reviews) is shown in the following table:
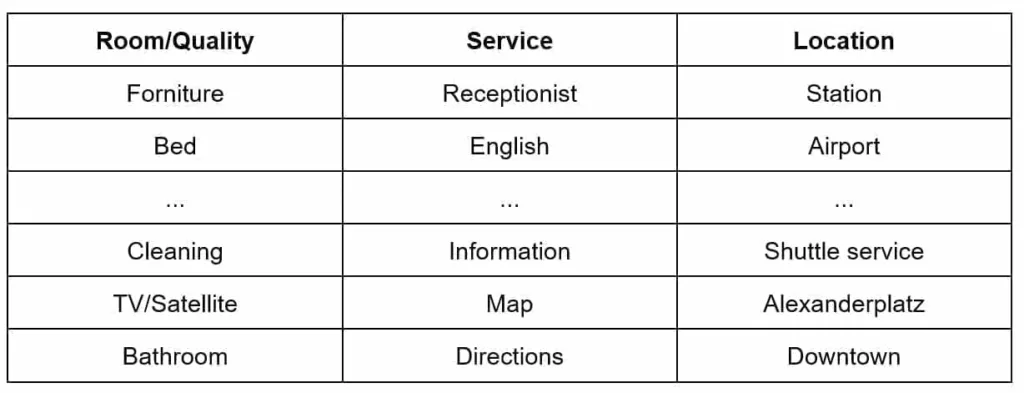
These are only a few selected words, but we filtered many redundant terms out during our analysis. However, it’s easy to check that, for example:
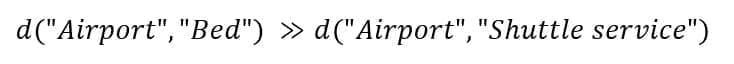
To understand the reviews and exploit them to create user profiles, we have also employed a sentiment analysis model, which is trained to perform what we have called “vestigial analysis.” In other words, we need to extract the sentiment of every agnostic word (like “Bed”) considering a small surrounding context. Let’s consider the following example:
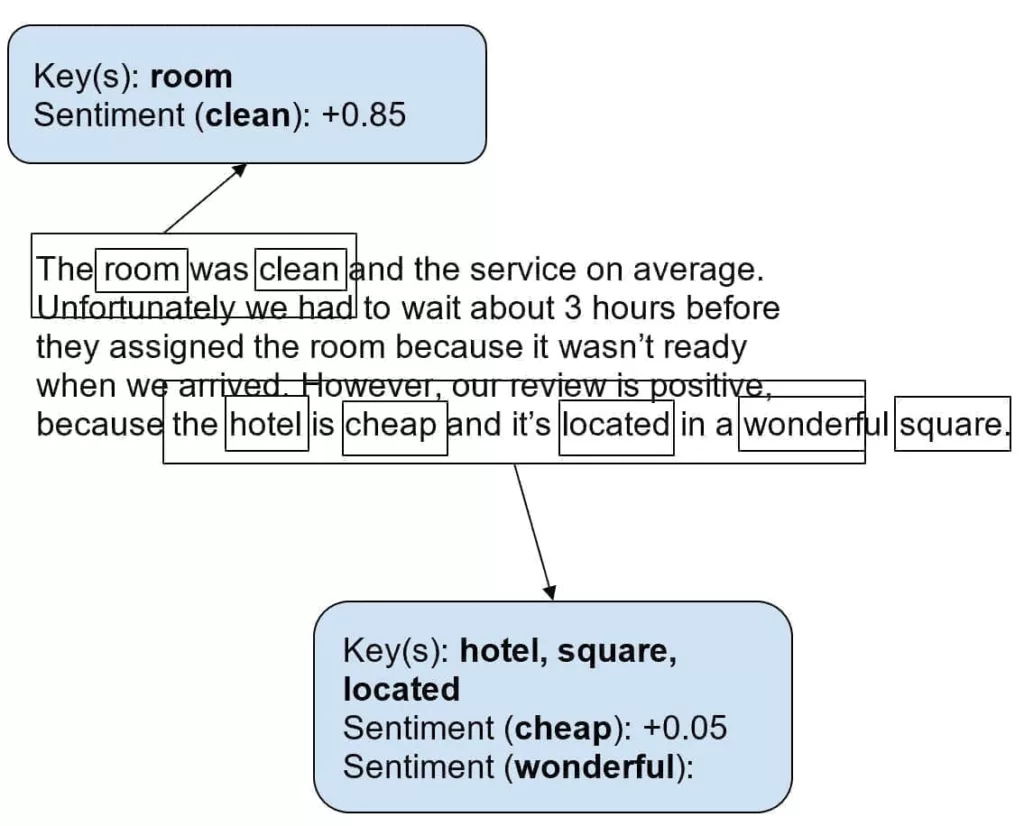
Considering the previous example, we want to create a sparse feature vector as a function of the user and the item:
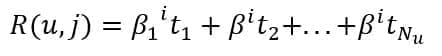
Every coefficient represents the specific topic’s average sentiment (normalized between -1.0 and 1.0). As each review covers only a subset of topics, we assume most Beta = 0. For example, in the previous case, we are considering only the keywords room, hotel, square, and located, which refer to the topics t1 = {Room. Quality} and t3 = {Location}. In this case, the attribute “cheap” has a neutral sentiment because this word can also be used to define poor-quality hotels. The resulting vector becomes:
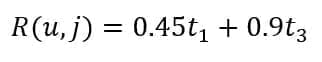
Once all the reviews have been processed (at the beginning, the process is purely batch, but it becomes incremental during the production phase), we can obtain the user-profile feature vectors as:
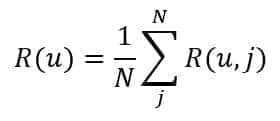
The resulting vector contains an average of all topics with a weight obtained through the sentiment analysis. In particular scenarios, we have also tested the possibility of reweighting the coefficients according to the global average or secondary factors. This approach allows us to avoid undesired biases for topics that should be secondary.
The neural model to perform the sentiment analysis is shown in the following schema:
The dataset has been labeled, selecting the keywords and their relative sentiment. The role of the “Word vector selector” is to create an “attention mechanism” that allows focusing only on the relevant parts. In particular, it receives the whole sequence and the positions of the target keys and outputs a synthetic vector fed into the following sub-network.
To exploit the composition ability of word vectors, we have implemented 1D convolutions that can evaluate the local relationships. Horizontal pooling layers didn’t boost the performances as expected and have been excluded. All convolutions are based on ReLU activations.
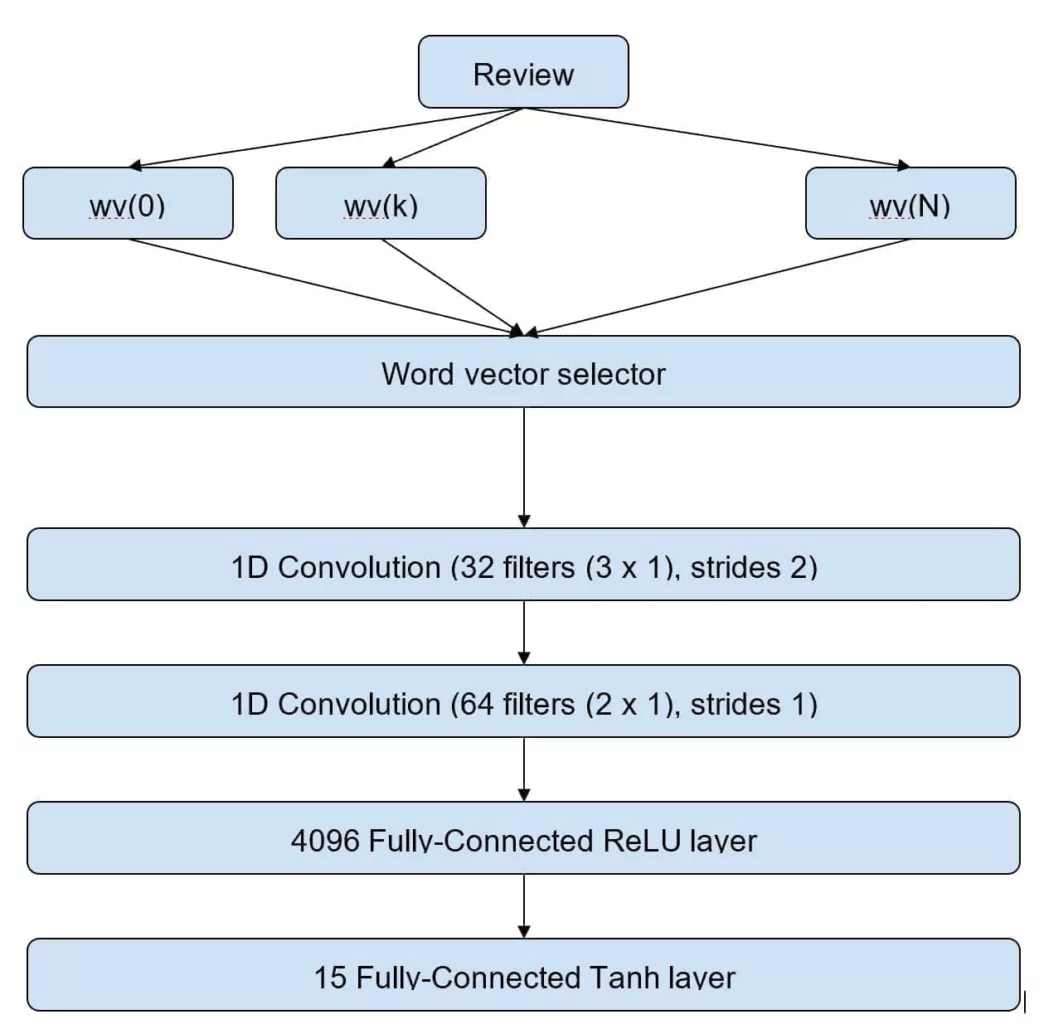
The output of the network is made up of 15 hyperbolic tangent units that represent the sentiment for each topic. This choice allowed neutral sentiments to be discarded as their value is close to zero. In our practical implementation, we have thresholded the output to accept absolute values greater than 0.1. This choice allowed us to denoise the predictions while maintaining accuracy. The training was performed using 480,000 reviews, and the validation was done on 20,000 reviews. The final validation accuracy is about 88%, but deeper models with larger corpora perform better. An alternative approach is based on an LSTM layer that captures the structural sequence of the review:
LSTMs are extremely useful when the reviews are not very short. In this case, the peculiar ability to discover long-term dependencies allows us to process contexts where the target keyword and the qualifying elements are not very close. For example, a sentence like: “The hotel that we booked using the Acme service suggested by a friend of ours is excellent” requires more complex processing to avoid the network remaining stuck in short contexts. Seq2Seq, with attention, has been successfully tested to output synthetic vectors where the most critical elements are immediately processable. We have also noticed that convolutions learn much faster when they cope with standardized structures. This approach and other improvements are the goal of future developments.
From User Profiles to Recommendations
Once all the reviews have been processed, the feature vectors can be directly employed for recommendations. In particular, we have tested and implemented the following solutions:
-
- User clustering: in this case, the users are grouped using K-Means and Spectral Clustering (particularly useful as the clusters are often non-convex) at a higher level. Then, each cluster is mapped using a Ball-Tree, and a k-Nearest Neighbors algorithm selects the most similar users according to a variable radius. As the feature vectors represent the comments and latent wishes, very close users can share their experiences, and hence, the engine suggests new items in a discovery section. This approach is an example of collaborative filtering that can be customized with extra parameters (real-time suggestions, proximity to an event place, and so on).
- Local suggestion: whenever geospatial-constrained recommendations are necessary, we can force the weight of a topic (e.g., close to an airport), or, when possible, we use the mobile GPS to determine the position and create a local neighborhood.
- Item-tag-match: When the items are tagged, the profiles are exploited in two ways:
- To re-evaluate the tagging (e.g., “The hotel has satellite TV” is identified as false by the majority of reviews, and its weight is decreased)
- To match users and items immediately without the need for collaborative filtering or other clustering approaches
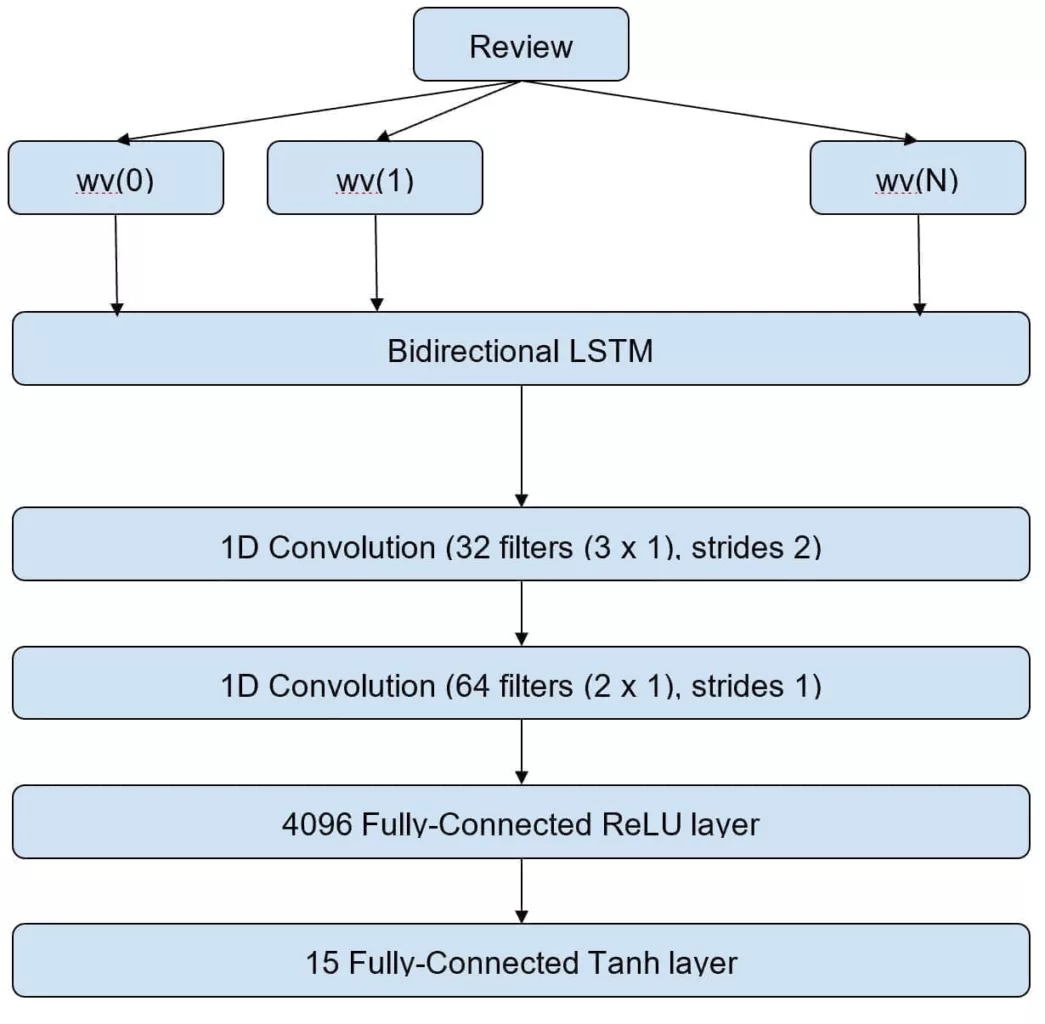
Moreover, the user-profile network has been designed to consider a feedback system, as shown in the following figure:
The goal is to reweight the recommendations considering the common factors between each item and the user profile. Suppose that item i has been recommended because it matches the favorable preference for the topics t1, t3, and t5. If the user sends a negative feedback message, the engine will reweight these topics using an exponential function (based on the number of received feedbacks). Conversely, positive feedback will increase the weight. The approach is based on a simple reinforcement learning strategy but allows fine-tuning based on each user.
Conclusions
Recommendations are becoming increasingly important, and, in many cases, the success of a service depends on them. Our experience taught us that reviews are more “accepted” than surveys and provide many more pieces of information than explicit feedback. Current deep learning techniques allow the processing of natural language and all jargon expressions in real-time with an accuracy comparable to that of a human agent. Moreover, whenever the reviews are prefiltered to remove all spam and meaningless ones, their content reflects every personal experience often much better than a simple rating. In our future developments, we plan to implement the engine in different industries, collecting reviews, together with public Tweets with specific hashtags and increasing the “vestigial sentiment analysis” ability with deeper models and different word-vectors strategies (like FastText that works with phonemes and doesn’t have a loss of performances with rare words).
References
-
- Blei D. M., Ng A. Y., Jordan M. I., Latent Dirichlet Allocation, Journal of Machine Learning Research 3/2003
- Das R., Zaheer M., Dyer C., Gaussian LDA for Topic Models with Word Embeddings, Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 07/2015
- Bonaccorso G., Machine Learning Algorithms, Packt Publishing, 2017
- Bonaccorso G., Mastering Machine Learning Algorithms, Packt Publishing, 2018
- Mikolov T., Sutskever I., Chen K., Corrado G., Dean J., Distributed Representations of Words and Phrases and their Compositionality, arXiv:1310.4546 [cs.CL]
- Pennington J., Socher R., Manning C. D., GloVe: Global Vectors for Word Representation, Stanford University
- Joulin A., Grave E., Bojanowski P., Mikolov T., Bag of Tricks for Efficient Text Classification, arXiv:1607.01759 [cs.CL]
- https://radimrehurek.com/gensim/models/word2vec.html
If you like this post, you can always donate to support my activity! One coffee is enough!