
This is a crash introduction to kernel methods, and the best thing to do is start with a very simple question. Is this bidimensional set linearly separable?
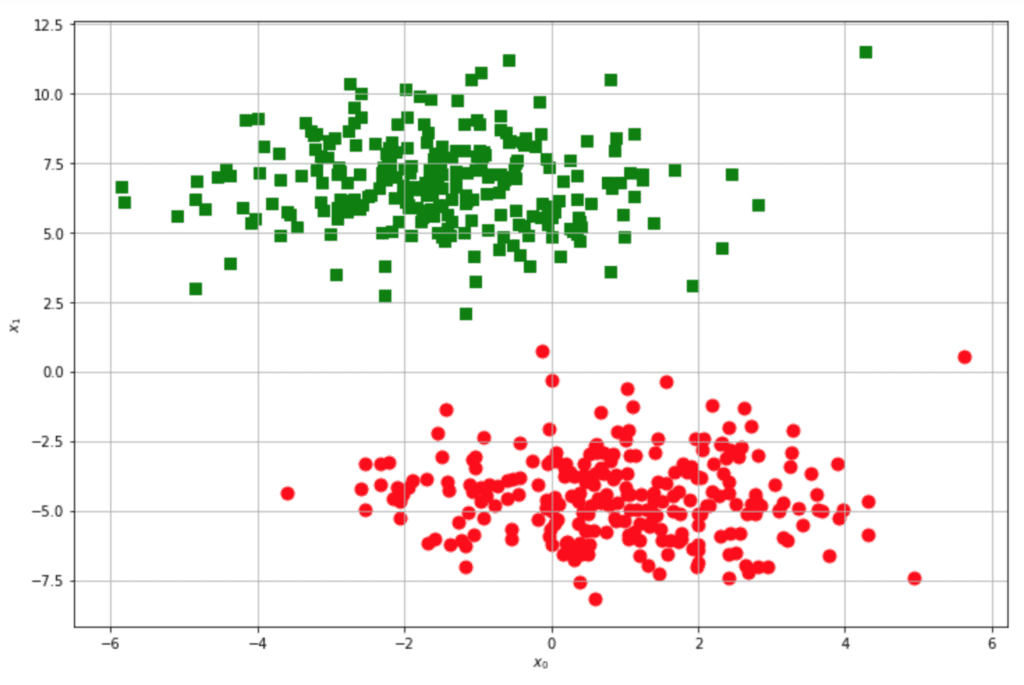
Of course, the answer is yes, it is. Why? A dataset defined in a subspace Ω ⊆ ℜn is linearly separable if there exists a (n-1)-dimensional hypersurface that is able to separate all points belonging to a class from the others. Let’s consider the problem from another viewpoint, supposing, for simplicity, to work in 2D.
We have defined a hypothetical separating line and set an arbitrary point O as an origin. Let’s now draw the vector w, orthogonal to the line, and point in one of the two sub-spaces. Let’s now consider the inner product between w and a random point x0: how can we decide if it’s on the side pointed by w? Simply put, the inner product is proportional to the cosine of the angle between the two vectors. If such an angle is between -π/2 and π/2, the cosine is non-negative, otherwise is non-positive:
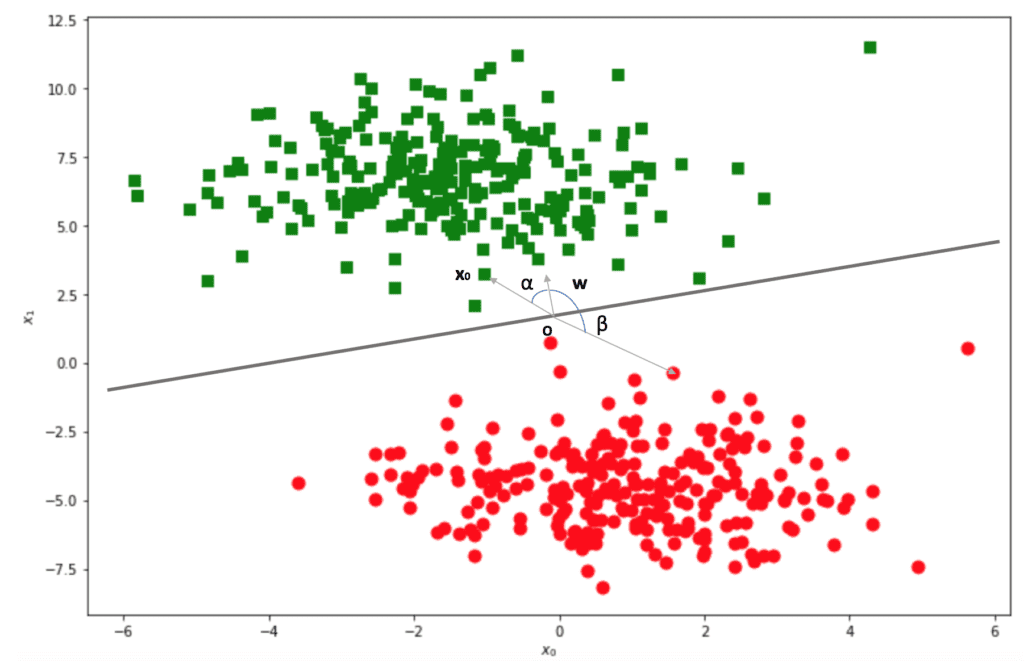
It’s to prove that all angles α between w and green dots are always bounded between -π/2 and π/2. Therefore, all inner products are positive (there are no points on the line where the cosine is 0). At the same time, all β angles are bounded between π/2 and 3π/2 where the cosine is negative.
Now, it should be obvious that w is the weight vector of a “pure” linear classifier (like a Perceptron), and the corresponding decision rule is:
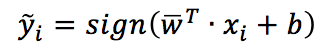
The way to determine w changes according to the algorithm, and so does the decision rule, which is always a function strictly related to the angle between w and the sample.
Let’s now consider another famous example: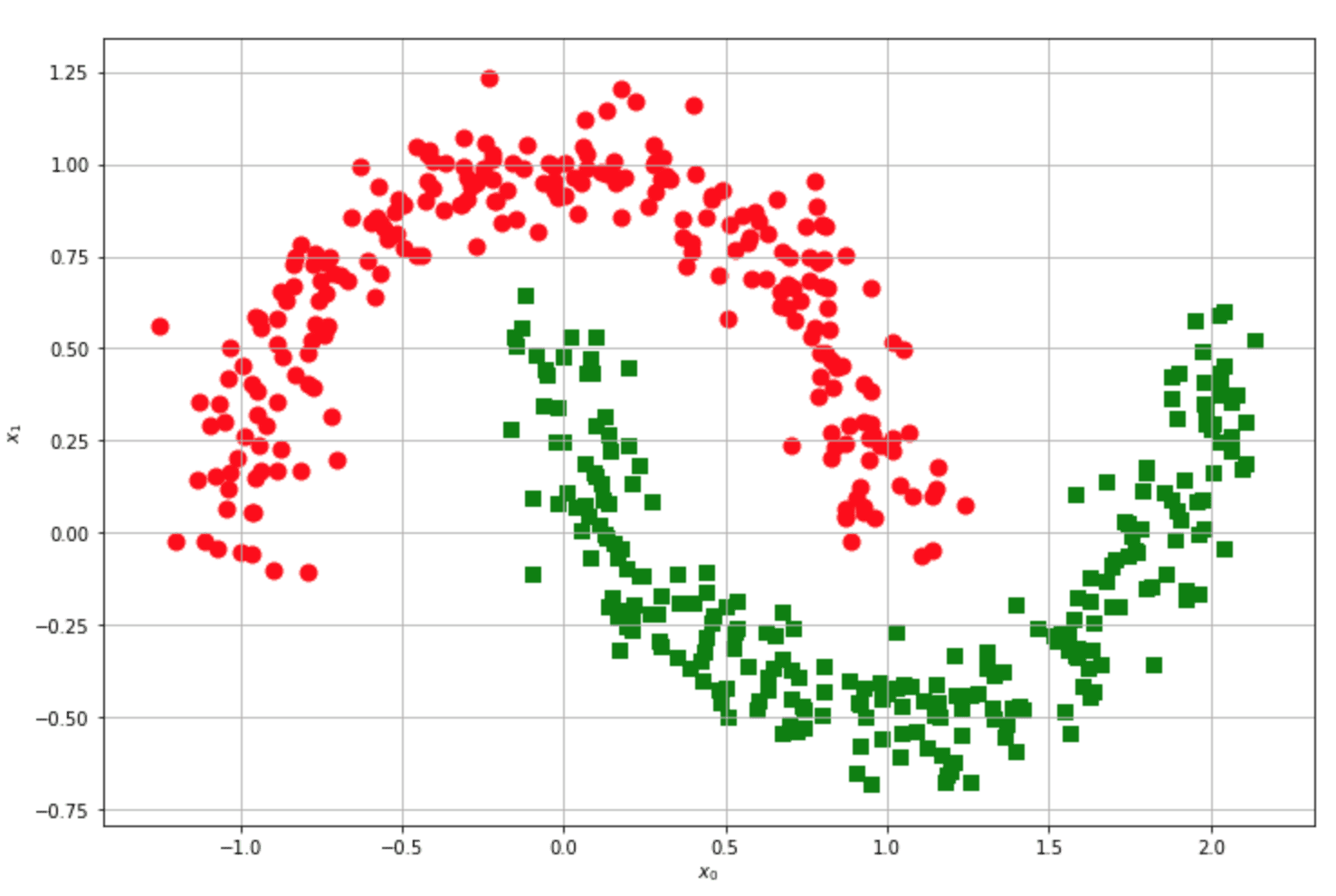
Is this dataset linearly separable? You’re free to try, but the answer is no. For every line you draw, red and green points will always be on the same side, so the accuracy can never overcome a fixed threshold (relatively low). Now, let’s suppose to protect the original dataset into a m-dimensional feature space (m can also be equal to n):
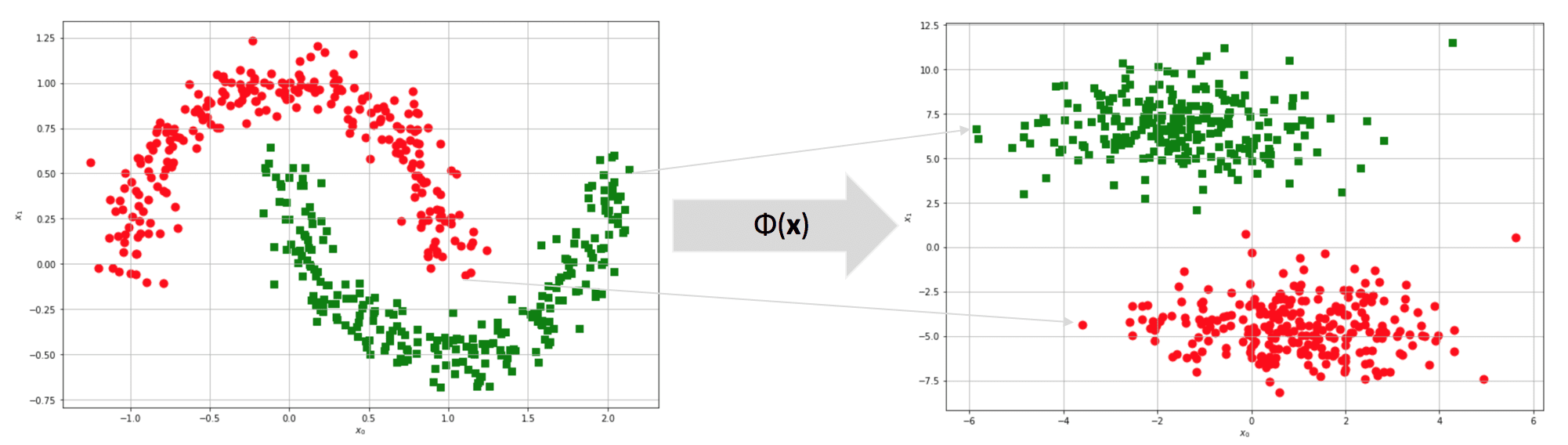
After the transformation, the original half-moon dataset becomes linearly separable! However, there’s still a problem: we need a classifier working in the original space to compute an inner product of transformed points. Let’s analyze the problem using the SVM (Support Vector Machines), where the kernels are very diffused. An SVM algorithm tries to maximize the separation between high-density blocks. I’m not covering all the details (which can be found in every Machine Learning book), but I need to define the expression for the weights:
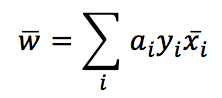
It’s not important if you don’t know how they are derived. It’s simpler to understand the final result: if you reconsider the previous image, where we had drawn a separating line, all green points have y=1. Therefore, w is the weighted sum of all samples. The values of αi are obtained through the optimization process; however, in the end, we should observe a w similar to what we arbitrarily drew.
If we need to move on to the feature space, every x must be filtered by φ(x). Therefore, we get:
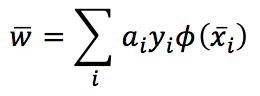
The corresponding decision function becomes:
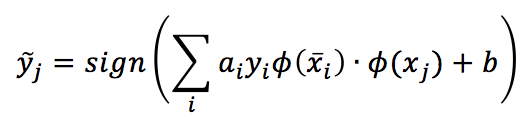
As the sum is extended to all samples, we must compute N inner products of transformed samples. This isn’t a properly fast solution! However, there are particular functions called kernels, which have a very nice property:
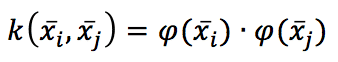
In other words, the kernel, evaluated at xi, xj, equals the inner product of the two points projected by a function ρ(x). Pay attention: ρ is another function because, if we start from the projection, we won’t be able to find a kernel, while if we start from the kernel, there is also a famous mathematical result (Mercer’s theorem) that guarantees given a continuous, symmetric a (semi-)positive definite kernel, the existence of an implicit transformation ρ(x) under some (easily met) conditions.
It’s not difficult to understand that by using a kernel, the decision function becomes:
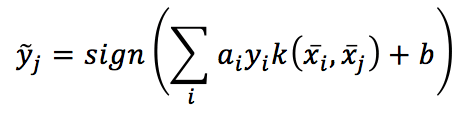
Which is much easier to evaluate.
Theoretically, we could try to find a kernel for a specific transformation, but in real life, only some kernels are useful in many different contexts. For example, the Radial Basis Function:
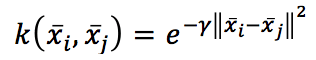
Which is excellent whenever we need to remap the original space into a radial one. Or the polynomial kernel:
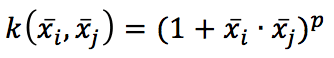
Which determines all the polynomial term features (like x2 or 2 xixj). There are also other kernels, like sigmoid or tanh, but starting with a linear classifier is always a good idea. If the accuracy is too low, it’s possible to try an RBF or polynomial kernel, then other variants, and if nothing works, it’s probably necessary to change the model!
Kernels are not limited to classifiers: they can be employed in PCA (Kernel PCA allows extracting the principal components from non-linear datasets and instance-based-learning algorithms. The principle is always the same (and it’s the kernel silver bullet: it represents the inner product of non-linear projections that can remap the original dataset in a higher dimensional space where it’s easier to find a linear solution).
If you like this post, you can always donate to support my activity! One coffee is enough!