
BBC News dataset (available for download on the Insight Project Resources website) is made up of 2225 news lines classified into five categories (Politics, Sport, Entertainment, Tech, Business) and, similarly to Reuters-21578, it can be employed to test both the efficacy and the efficiency of different classification strategies.
In the Github repository: https://github.com/giuseppebonaccorso/bbc_news_classification_comparison, I’ve committed a Jupyter (IPython) notebook (based on Scikit-Learn, NLTK, Gensim, Keras (with Theano or Tensorflow)) where I’ve collected some experiments aimed at comparing four different algorithms:
-
- Multinomial Naive-Bayes with Count (TF) vectorizer
- Multinomial Naive-Bayes with TF-IDF vectorizer
- SVM (linear and kernelized) with Doc2Vec (Gensim-based) vectorization
- MLP (Keras-based) with Doc2Vec vectorization
(Every experiment has been performed on tokens without stop-words and processed with WordNet lemmatization).
As expected (thanks to several research projects – see references for further information), Naive-Bayes performs even better than the other strategies, particularly comparing its simplicity and naiveness with the complexity of SVM and neural networks. Intuitively, a Naive-Bayes classifier determines a decision threshold according to observed data likelihood and, in particular, adopting a multinomial distribution allows to compute the probability of a particular sequence of tokens belonging to a specific class (under the assumption of conditional independence), starting from single likelihoods which are directly connected to token frequencies. It simply means that a machine-learning algorithm can learn in a way that is not so different from the criterion adopted by human beings when they read a piece of news for the first time and are asked to classify it.
For example, if we start reading: “Football club…”, the probability of class “Sports” is immediately pushed up by the likelihood of tokens like “football,” “club,” etc… However, suppose we continue reading: “…stock options, trading, market, stock exchange”. In that case, we’re driven to think that the main topic is likely related to the class “Business,” even if something belongs to “Sport,” which reduces the overall probability.
Conversely, Word2Vec (and Doc2Vec) algorithms adopt neural networks to learn the inner relationships among words and compute a vector space with a metric isomorphic to some sort of “probabilistic semantic.” In other words, the assumption is that all texts are structured with an intrinsic correlation among close words. In this way, it’s possible to learn a model that minimizes a loss function that represents the “distance” among tokens, and the same metric used to measure the distance between two vectors (points in a hyperspace) does the same with the semantics induced by the corpus.
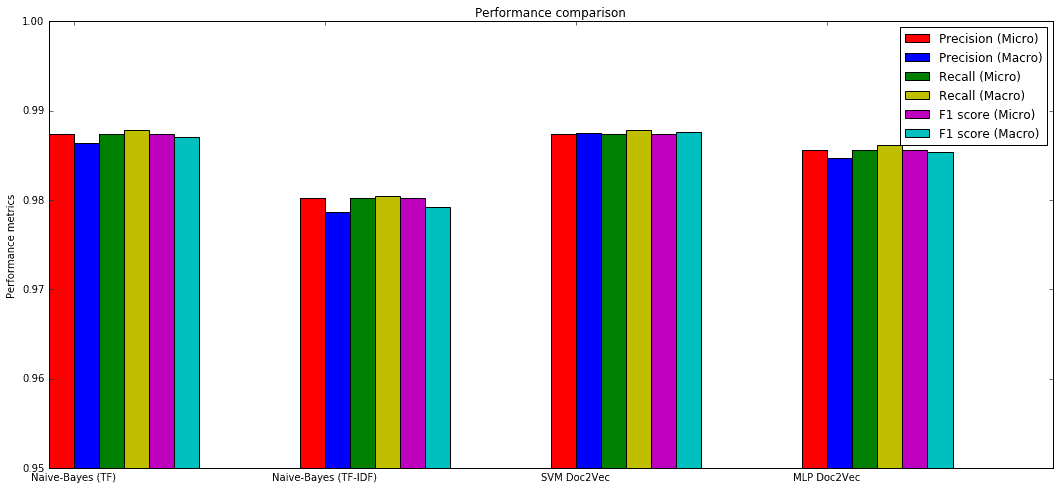
The summary of performance metrics (obtained after a Grid Search of optimal hyperparameters, even if, for example, MLPs are very sensitive to their architecture, activation functions, optimizers, etc., so it’s always a good idea trying with many algorithms, batch sizes and epochs, so to find out which combination best matches the requirements) is:
Multinomial Naive-Bayes with Count (TF) vectorizer:
Precision score: 0.987433 (micro) / 0.986406 (macro) Recall score: 0.987433 (micro) / 0.987845 (macro) F1 score: 0.987433 (micro) / 0.986997 (macro)
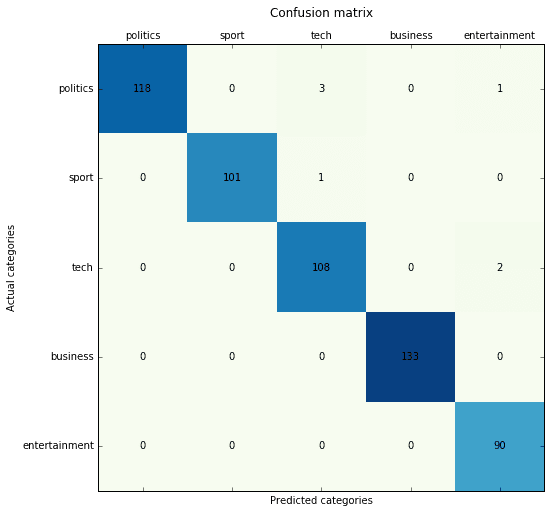
Multinomial Naive-Bayes with TF-IDF vectorizer:
Precision score: 0.980251 (micro) / 0.978598 (macro) Recall score: 0.980251 (micro) / 0.980466 (macro) F1 score: 0.980251 (micro) / 0.979228 (macro)
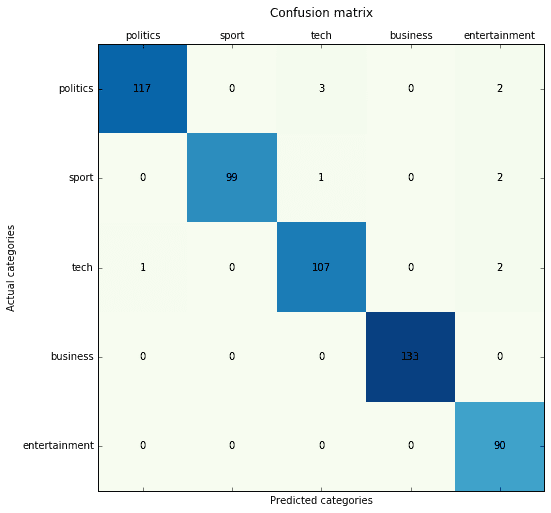
SVM (linear and kernelized) with Doc2Vec (Gensim-based) vectorization:
Doc2Vec models are sensitive to many parameters, and a long time is needed to perform a deep grid search. However, comparing the results, I think SVMs and MLPs perform similarly. In [3], you can find a theoretical proof of Naive-Bayes optimality under certain conditions. However, based on my experience, thanks to their high non-linearity, kernelized SVMs or MLPs can more accurately generalize when the resulting conditional dependence among parameters is higher.
Precision score: 0.987433 (micro) / 0.987537 (macro) Recall score: 0.987433 (micro) / 0.987811 (macro) F1 score: 0.987433 (micro) / 0.987666 (macro)
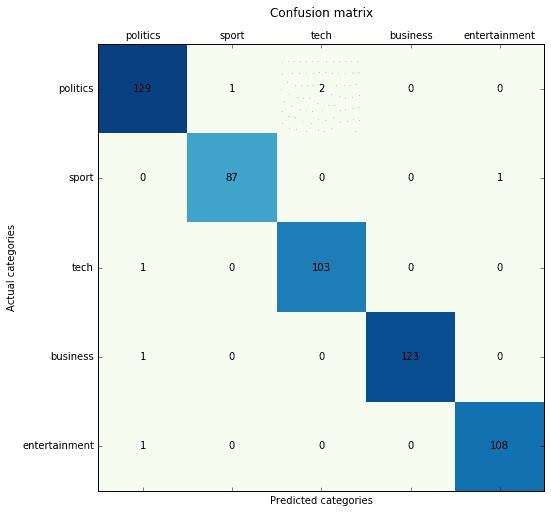
MLP (Keras-based) with Doc2Vec (Gensim-based) vectorization:
Precision score: 0.985637 (micro) / 0.984715 (macro) Recall score: 0.985637 (micro) / 0.986193 (macro) F1 score: 0.985637 (micro) / 0.985397 (macro)
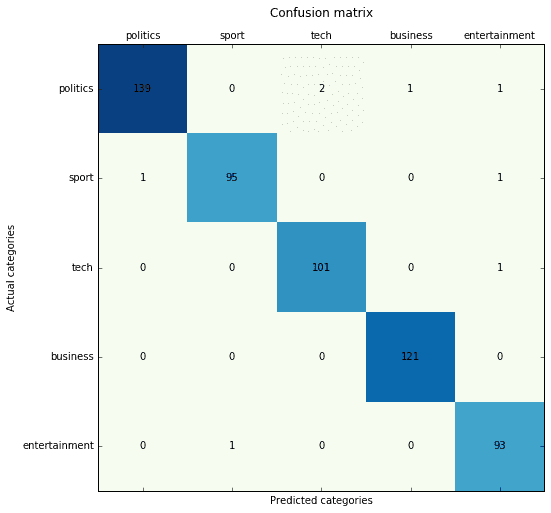
Performance comparison:
Theoretical references:
-
- D. Greene and P. Cunningham. “Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering,” Proc. ICML 2006
- Metsis, Vangelis, Ion Androutsopoulos, and Georgios Paliouras. “Spam Filtering with Naive Bayes-Which Naive Bayes?”, CEAS, 27–28, 2006
- Zhang, Harry. “The Optimality of Naive Bayes.”, AA 1, no. 2 (2004): 3
- Le, Quoc V., and Tomas Mikolov. “Distributed Representations of Sentences and Documents,” ICML, 14:1188–1196, 2014
- Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient Estimation of Word Representations in Vector Space,” arXiv Preprint arXiv:1301.3781, 2013
- Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S. Corrado, and Jeff Dean. “Distributed Representations of Words and Phrases and Their Compositionality,” Advances in Neural Information Processing Systems, 3111–3119, 2013
If you like this poem, you can always donate to support my activity! One coffee is enough!