
Il set di dati di BBC News (disponibile per il download sul sito web Insight Project Resources) è composto da 2225 righe di notizie classificate in cinque categorie (Politica, Sport, Intrattenimento, Tecnologia, Affari) e, analogamente a Reuters-21578, può essere utilizzato per testare sia l’efficacia che l’efficienza di diverse strategie di classificazione.
Nel repository Github: https://github.com/giuseppebonaccorso/bbc_news_classification_comparison, ho impegnato un taccuino Jupyter (IPython) (basato su Scikit-Learn, NLTK, Gensim, Keras (con Theano o Tensorflow)) dove ho raccolto alcuni esperimenti volti a confrontare quattro diversi algoritmi:
-
- Naive-Bayes multinomiale con vettorizzatore Count (TF)
- Naive-Bayes multinomiale con vettorizzatore TF-IDF
- SVM (lineare e kernelizzata) con vettorizzazione Doc2Vec (basata su Gensim)
- MLP (basato su Keras) con vettorizzazione Doc2Vec
(Ogni esperimento è stato eseguito su token senza stop-words ed elaborati con la lemmatizzazione WordNet).
Come previsto (grazie a diversi progetti di ricerca – si vedano i riferimenti per ulteriori informazioni), Naive-Bayes si comporta ancora meglio delle altre strategie, in particolare confrontando la sua semplicità e ingenuità con la complessità di SVM e delle reti neurali. Intuitivamente, un classificatore Naive-Bayes determina una soglia decisionale in base alla probabilità dei dati osservati e, in particolare, l’adozione di una distribuzione multinomiale permette di calcolare la probabilità di una particolare sequenza di token appartenenti a una classe specifica (sotto l’ipotesi di indipendenza condizionale), partendo da probabilità singole che sono direttamente collegate alle frequenze dei token. Significa semplicemente che un algoritmo di apprendimento automatico può imparare in un modo che non è molto diverso dal criterio adottato dagli esseri umani quando leggono una notizia per la prima volta e gli viene chiesto di classificarla.
Per esempio, se iniziamo a leggere: “Club di calcio…”, la probabilità della classe “Sport” viene immediatamente spinta verso l’alto dalla probabilità di token come “calcio”, “club”, ecc…. Tuttavia, supponiamo di continuare a leggere: “…stock options, trading, mercato, borsa”. In questo caso, siamo portati a pensare che l’argomento principale sia probabilmente legato alla classe “Business”, anche se qualcosa appartiene a “Sport”, il che riduce la probabilità complessiva.
Al contrario, gli algoritmi Word2Vec (e Doc2Vec) adottano reti neurali per apprendere le relazioni interne tra le parole e calcolano uno spazio vettoriale con una metrica isomorfa a una sorta di “semantica probabilistica”. In altre parole, l’ipotesi è che tutti i testi siano strutturati con una correlazione intrinseca tra parole vicine. In questo modo, è possibile apprendere un modello che minimizza una funzione di perdita che rappresenta la ‘distanza’ tra i token, e la stessa metrica utilizzata per misurare la distanza tra due vettori (punti in un iperspazio) fa lo stesso con la semantica indotta dal corpus.
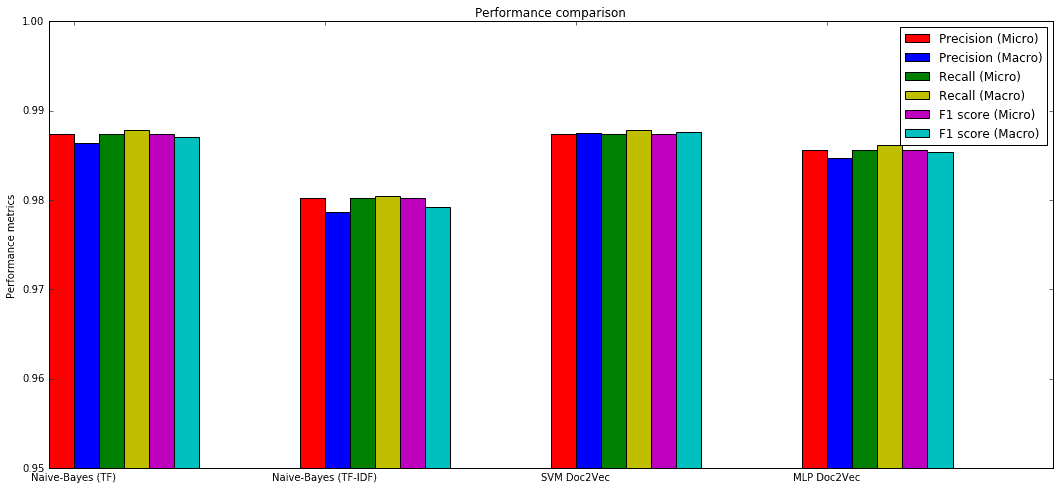
Il riepilogo delle metriche delle prestazioni (ottenute dopo una ricerca a griglia degli iperparametri ottimali, anche se, ad esempio, le MLP sono molto sensibili alla loro architettura, alle funzioni di attivazione, agli ottimizzatori, eccetera, per cui è sempre una buona idea provare con molti algoritmi, dimensioni dei lotti ed epoche, in modo da scoprire quale combinazione corrisponde meglio ai requisiti) è:
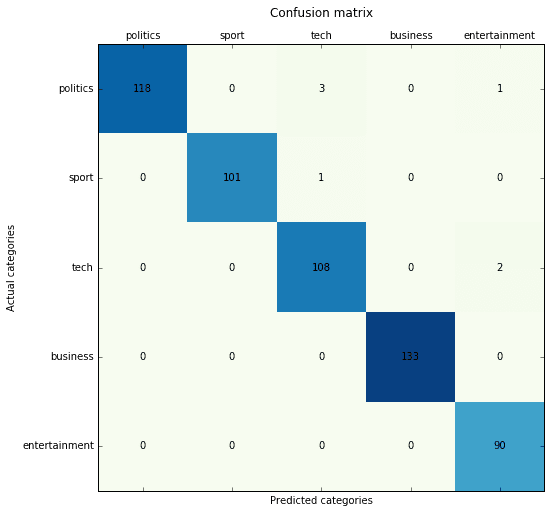
Naive-Bayes multinomiale con vettorizzatore Count (TF):
Precision score: 0.987433 (micro) / 0.986406 (macro) Recall score: 0.987433 (micro) / 0.987845 (macro) F1 score: 0.987433 (micro) / 0.986997 (macro)
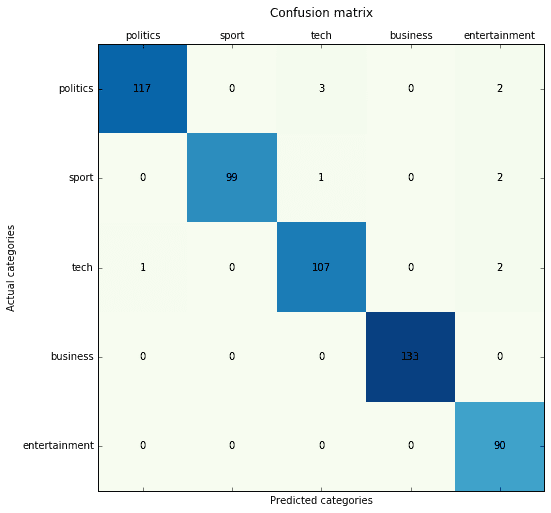
Naive-Bayes multinomiale con vettorizzatore TF-IDF:
Precision score: 0.980251 (micro) / 0.978598 (macro) Recall score: 0.980251 (micro) / 0.980466 (macro) F1 score: 0.980251 (micro) / 0.979228 (macro)
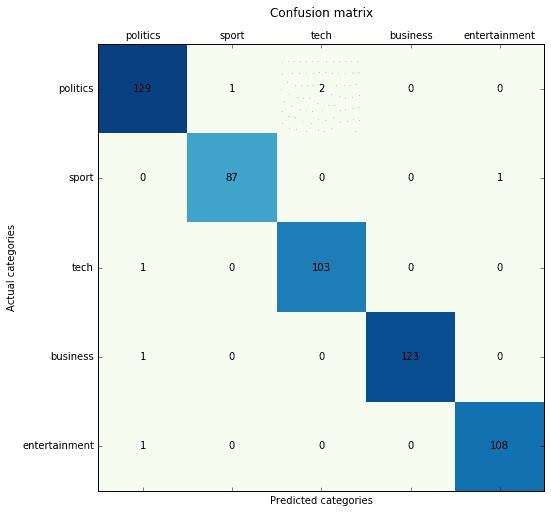
SVM (lineare e kernelizzata) con vettorizzazione Doc2Vec (basata su Gensim):
I modelli Doc2Vec sono sensibili a molti parametri e occorre molto tempo per eseguire una ricerca a griglia profonda. Tuttavia, confrontando i risultati, credo che SVM e MLP abbiano prestazioni simili. In [3], è possibile trovare una prova teorica dell’ottimalità di Naive-Bayes in determinate condizioni. Tuttavia, in base alla mia esperienza, grazie alla loro elevata non linearità, le SVM o le MLP kernelizzate possono generalizzare in modo più accurato quando la dipendenza condizionale risultante tra i parametri è più elevata.
Precision score: 0.987433 (micro) / 0.987537 (macro) Recall score: 0.987433 (micro) / 0.987811 (macro) F1 score: 0.987433 (micro) / 0.987666 (macro)
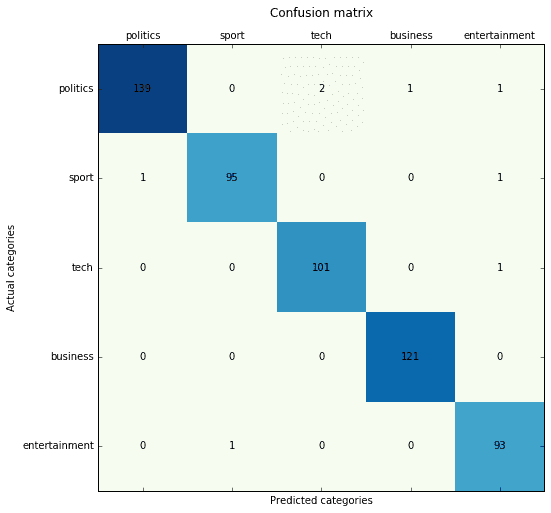
MLP (basato su Keras) con vettorizzazione Doc2Vec (basato su Gensim):
Precision score: 0.985637 (micro) / 0.984715 (macro) Recall score: 0.985637 (micro) / 0.986193 (macro) F1 score: 0.985637 (micro) / 0.985397 (macro)
Confronto delle prestazioni:
Riferimenti teorici:
-
- D. Greene and P. Cunningham. “Practical Solutions to the Problem of Diagonal Dominance in Kernel Document Clustering,” Proc. ICML 2006
- Metsis, Vangelis, Ion Androutsopoulos, and Georgios Paliouras. “Spam Filtering with Naive Bayes-Which Naive Bayes?”, CEAS, 27–28, 2006
- Zhang, Harry. “The Optimality of Naive Bayes.”, AA 1, no. 2 (2004): 3
- Le, Quoc V., and Tomas Mikolov. “Distributed Representations of Sentences and Documents,” ICML, 14:1188–1196, 2014
- Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeffrey Dean. “Efficient Estimation of Word Representations in Vector Space,” arXiv Preprint arXiv:1301.3781, 2013
- Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S. Corrado, and Jeff Dean. “Distributed Representations of Words and Phrases and Their Compositionality,” Advances in Neural Information Processing Systems, 3111–3119, 2013
Se ti piace l’articolo, puoi sempre fare una donazione per supportare la mia attività. Basta un caffè!