
Word2Vec (https://code.google.com/archive/p/word2vec/) offers an exciting alternative to classical NLP based on term-frequency matrices. In particular, as each word is embedded into a high-dimensional vector, it’s possible to consider a sentence like a sequence of points that determine an implicit geometry. For this reason, considering 1D convolutional classifiers (usually very efficient with images) became a concrete possibility.
As you know, a convolutional network trains its kernels to be able to capture initially coarse-grained features (like the orientation), and while the kernel size decreases, more and more detailed elements (like eyes, wheels, hands, and so forth). In the same way, a 1D convolution works on 1-dimensional vectors (in general, they are temporal sequences), extracting pseudo-geometric features.
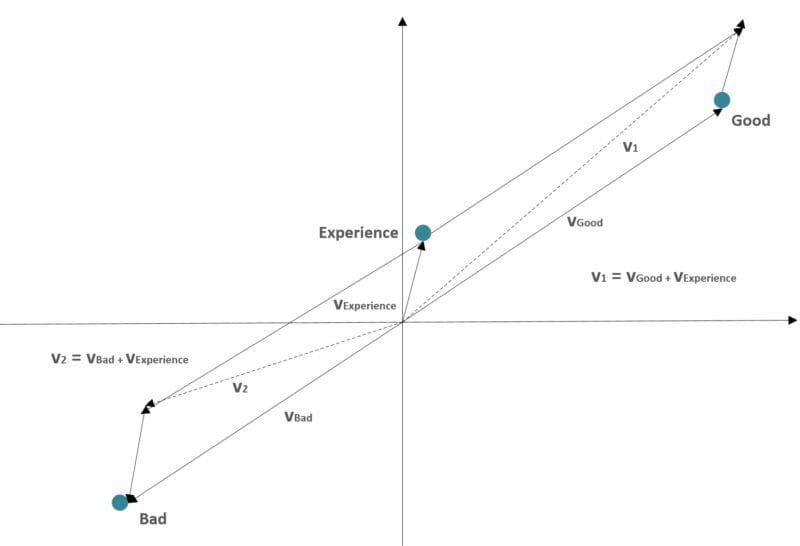
The rationale is provided by the Word2Vec algorithm: as the vectors are “grouped” according to a semantic criterion so that two similar words have very close representations, a sequence can be considered as a piecewise function, whose “shape” has a strong relationship with the semantic components. In the previous image, two sentences are considered as vectorial sums:
-
- v1: “Good experience”
- v2: “Bad experience”
As it’s possible to see, the resulting vectors have different directions because the words “good” and “bad” have opposite representations. This condition allows “geometrical” language manipulations similar to what happens in an image convolutional network, allowing us to achieve results that can outperform standard Bag-of-words methods (like Tf-Idf).
To test this approach, I’ve used the Twitter Sentiment Analysis Dataset (http://thinknook.com/wp-content/uploads/2012/09/Sentiment-Analysis-Dataset.zip), which is made of about 1.400.000 labeled tweets. The dataset is quite noisy, and the overall validation accuracy of many standard algorithms is always about 75%.
For the Word2Vec, there are some alternative scenarios:
-
- Gensim (the best choice in the majority of cases) – https://radimrehurek.com/gensim/index.html
- Custom implementations based on NCE (Noise Contrastive Estimation) or Hierarchical Softmax. They are pretty easy to implement with Tensorflow but need extra effort, which is often unnecessary.
- An initial embedding layer. This approach is the simplest. However, the training performances are worse because the same network has to learn good word representations and, at the same time, optimize its weights to minimize the output cross-entropy.
I prefer to train a Gensim Word2Vec model with a vector size equal to 512 and a window of 10 tokens. The training set is made up of 1.000.000 tweets and the test set by 100.000 tweets. Both sets are shuffled before all epochs. As the average length of a tweet is about 11 tokens (with a maximum of 53), I’ve decided to fix the max length equal to 15 tokens (of course, this value can be increased, but for the majority of tweets, the convolutional network input will be padded with many blank vectors).
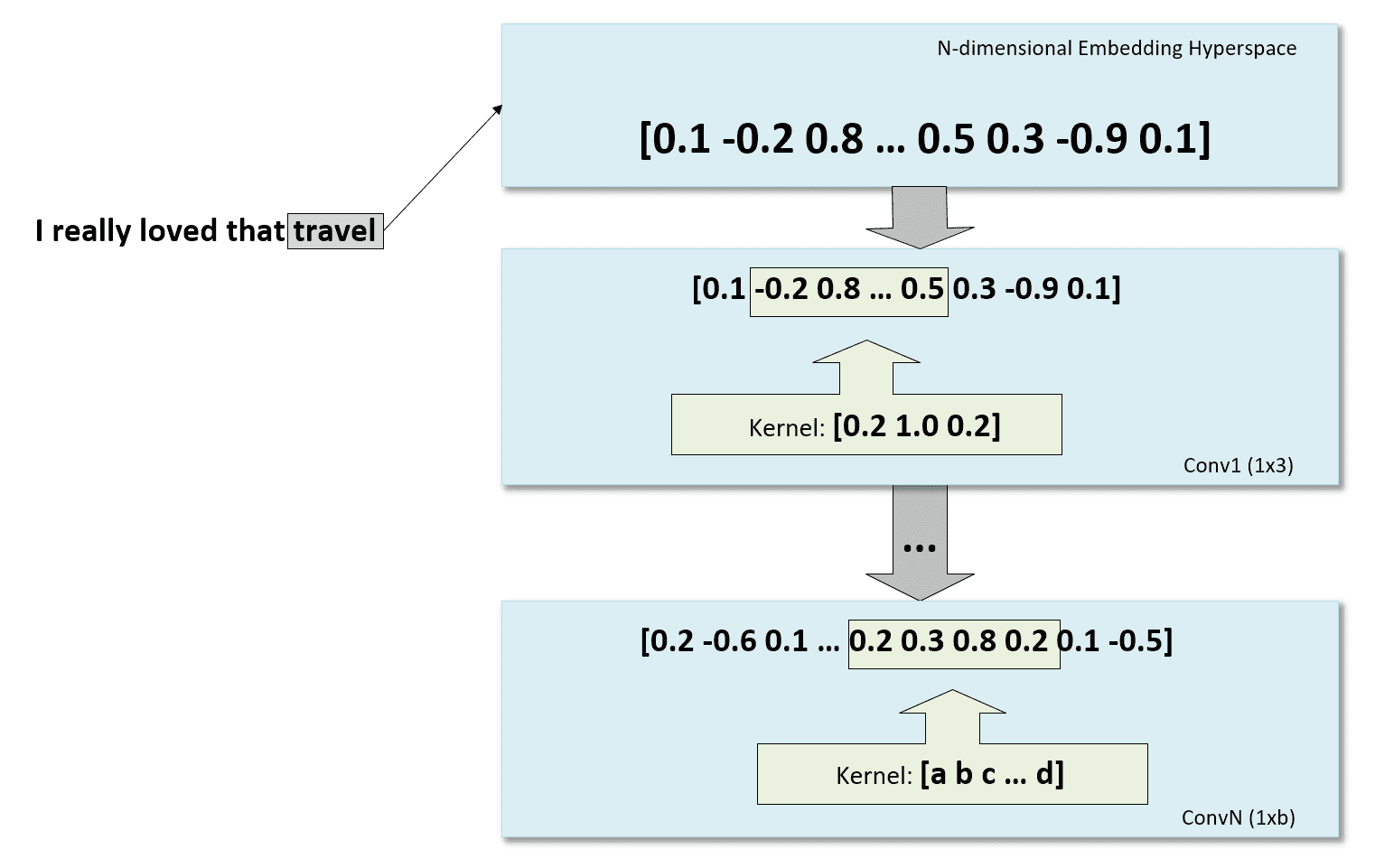
In the following figure, there’s a schematic representation of the process, starting from the word embedding and continuing with some 1D convolutions:
The whole code (copied into this GIST and also available in the repository: https://github.com/giuseppebonaccorso/twitter_sentiment_analysis_word2vec_convnet) is:
import keras.backend as K
import multiprocessing
import tensorflow as tf
from gensim.models.word2vec import Word2Vec
from keras.callbacks import EarlyStopping
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Flatten
from keras.layers.convolutional import Conv1D
from keras.optimizers import Adam
from nltk.stem.lancaster import LancasterStemmer
from nltk.tokenize import RegexpTokenizer
# Set random seed (for reproducibility)
np.random.seed(1000)
# Select whether using Keras with or without GPU support
# See: https://stackoverflow.com/questions/40690598/can-keras-with-tensorflow-backend-be-forced-to-use-cpu-or-gpu-at-will
use_gpu = True
config = tf.ConfigProto(intra_op_parallelism_threads=multiprocessing.cpu_count(),
inter_op_parallelism_threads=multiprocessing.cpu_count(),
allow_soft_placement=True,
device_count = {'CPU' : 1,
'GPU' : 1 if use_gpu else 0})
session = tf.Session(config=config)
K.set_session(session)
dataset_location = '/twitter/dataset.csv'
model_location = '/twitter/model/'
corpus = []
labels = []
# Parse tweets and sentiments
with open(dataset_location, 'r', encoding='utf-8') as df:
for i, line in enumerate(df):
if i == 0:
# Skip the header
continue
parts = line.strip().split(',')
# Sentiment (0 = Negative, 1 = Positive)
labels.append(int(parts[1].strip()))
# Tweet
tweet = parts[3].strip()
if tweet.startswith('"'):
tweet = tweet[1:]
if tweet.endswith('"'):
tweet = tweet[::-1]
corpus.append(tweet.strip().lower())
print('Corpus size: {}'.format(len(corpus)))
# Tokenize and stem
tkr = RegexpTokenizer('[a-zA-Z0-9@]+')
stemmer = LancasterStemmer()
tokenized_corpus = []
for i, tweet in enumerate(corpus):
tokens = [stemmer.stem(t) for t in tkr.tokenize(tweet) if not t.startswith('@')]
tokenized_corpus.append(tokens)
# Gensim Word2Vec model
vector_size = 512
window_size = 10
# Create Word2Vec
word2vec = Word2Vec(sentences=tokenized_corpus,
size=vector_size,
window=window_size,
negative=20,
iter=50,
seed=1000,
workers=multiprocessing.cpu_count())
# Copy word vectors and delete Word2Vec model and original corpus to save memory
X_vecs = word2vec.wv
del word2vec
del corpus
# Train subset size (0 < size < len(tokenized_corpus))
train_size = 1000000
# Test subset size (0 < size < len(tokenized_corpus) - train_size)
test_size = 100000
# Compute average and max tweet length
avg_length = 0.0
max_length = 0
for tweet in tokenized_corpus:
if len(tweet) > max_length:
max_length = len(tweet)
avg_length += float(len(tweet))
print('Average tweet length: {}'.format(avg_length / float(len(tokenized_corpus))))
print('Max tweet length: {}'.format(max_length))
# Tweet max length (number of tokens)
max_tweet_length = 15
# Create train and test sets
# Generate random indexes
indexes = set(np.random.choice(len(tokenized_corpus), train_size + test_size, replace=False))
X_train = np.zeros((train_size, max_tweet_length, vector_size), dtype=K.floatx())
Y_train = np.zeros((train_size, 2), dtype=np.int32)
X_test = np.zeros((test_size, max_tweet_length, vector_size), dtype=K.floatx())
Y_test = np.zeros((test_size, 2), dtype=np.int32)
for i, index in enumerate(indexes):
for t, token in enumerate(tokenized_corpus[index]):
if t >= max_tweet_length:
break
if token not in X_vecs:
continue
if i < train_size:
X_train[i, t, :] = X_vecs[token]
else:
X_test[i - train_size, t, :] = X_vecs[token]
if i < train_size:
Y_train[i, :] = [1.0, 0.0] if labels[index] == 0 else [0.0, 1.0]
else:
Y_test[i - train_size, :] = [1.0, 0.0] if labels[index] == 0 else [0.0, 1.0]
# Keras convolutional model
batch_size = 32
nb_epochs = 100
model = Sequential()
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same', input_shape=(max_tweet_length, vector_size)))
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same'))
model.add(Dropout(0.25))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='tanh'))
model.add(Dense(256, activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])
# Fit the model
model.fit(X_train, Y_train,
batch_size=batch_size,
shuffle=True,
epochs=nb_epochs,
validation_data=(X_test, Y_test),
callbacks=[EarlyStopping(min_delta=0.00025, patience=2)])
1000000/1000000 [==============================] - 240s - loss: 0.5171 - acc: 0.7492 - val_loss: 0.4769 - val_acc: 0.7748 Epoch 2/100 1000000/1000000 [==============================] - 213s - loss: 0.4922 - acc: 0.7643 - val_loss: 0.4640 - val_acc: 0.7814 Epoch 3/100 1000000/1000000 [==============================] - 230s - loss: 0.4801 - acc: 0.7710 - val_loss: 0.4581 - val_acc: 0.7839 Epoch 4/100 1000000/1000000 [==============================] - 197s - loss: 0.4729 - acc: 0.7755 - val_loss: 0.4525 - val_acc: 0.7860 Epoch 5/100 1000000/1000000 [==============================] - 185s - loss: 0.4677 - acc: 0.7785 - val_loss: 0.4493 - val_acc: 0.7887 Epoch 6/100 1000000/1000000 [==============================] - 183s - loss: 0.4637 - acc: 0.7811 - val_loss: 0.4455 - val_acc: 0.7917 Epoch 7/100 1000000/1000000 [==============================] - 183s - loss: 0.4605 - acc: 0.7832 - val_loss: 0.4426 - val_acc: 0.7938 Epoch 8/100 1000000/1000000 [==============================] - 189s - loss: 0.4576 - acc: 0.7848 - val_loss: 0.4422 - val_acc: 0.7934 Epoch 9/100 1000000/1000000 [==============================] - 193s - loss: 0.4552 - acc: 0.7863 - val_loss: 0.4412 - val_acc: 0.7942 Epoch 10/100 1000000/1000000 [==============================] - 197s - loss: 0.4530 - acc: 0.7876 - val_loss: 0.4431 - val_acc: 0.7934 Epoch 11/100 1000000/1000000 [==============================] - 201s - loss: 0.4508 - acc: 0.7889 - val_loss: 0.4415 - val_acc: 0.7947 Epoch 12/100 1000000/1000000 [==============================] - 204s - loss: 0.4489 - acc: 0.7902 - val_loss: 0.4415 - val_acc: 0.7938
The training was stopped by the Early Stopping callback after the twelfth iteration when the validation accuracy was about 79.4%, with a validation loss of 0.44.
Possible improvements or experiments I’m going to try are:
-
- Different word vector size (I’ve already tried with 128 and 256, but I’d like to save more memory)
- Embedding layer
- Average or max pooling to reduce the dimensionality
- Different architectures
The previous model has been trained on a GTX 1080 in about 40 minutes.
If you like this post, you can always donate to support my activity! One coffee is enough!