
Word2Vec (https://code.google.com/archive/p/word2vec/) offre un’interessante alternativa alla PNL classica basata sulle matrici di frequenza dei termini. In particolare, poiché ogni parola è inserita in un vettore ad alta dimensionalità, è possibile considerare una frase come una sequenza di punti che determinano una geometria implicita. Per questo motivo, considerare i classificatori convoluzionali 1D (di solito molto efficienti con le immagini) è diventata una possibilità concreta.
Come sa, una rete convoluzionale addestra i suoi kernel per essere in grado di catturare inizialmente caratteristiche a grana grossa (come l’orientamento) e, mentre la dimensione del kernel diminuisce, elementi sempre più dettagliati (come occhi, ruote, mani e così via). Allo stesso modo, una convoluzione 1D lavora su vettori a 1 dimensione (in genere, sono sequenze temporali), estraendo caratteristiche pseudo-geometriche.
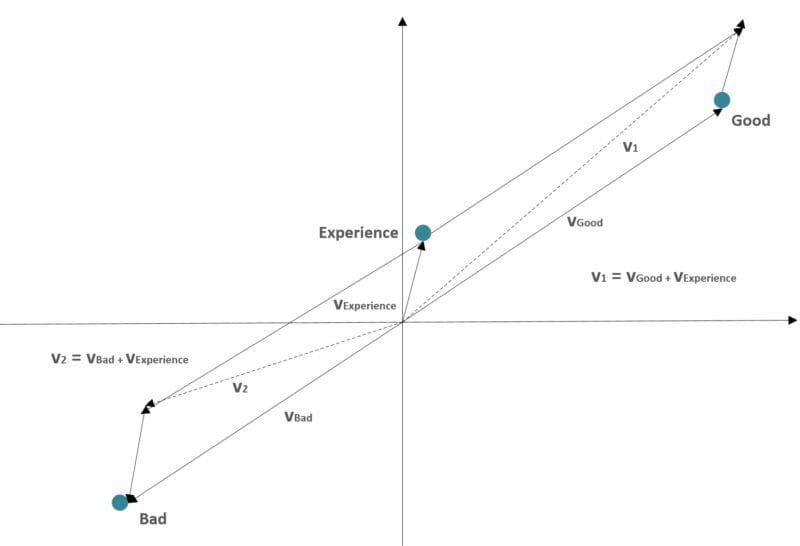
La logica è fornita dall’algoritmo Word2Vec: poiché i vettori sono ‘raggruppati’ in base a un criterio semantico, in modo che due parole simili abbiano rappresentazioni molto vicine, una sequenza può essere considerata come una funzione a pezzi, la cui ‘forma’ ha una forte relazione con i componenti semantici. Nell’immagine precedente, due frasi sono considerate come somme vettoriali:
-
- v1: “Buona esperienza”
- v2: “Pessima esperienza”
Come si può vedere, i vettori risultanti hanno direzioni diverse perché le parole “buono” e “cattivo” hanno rappresentazioni opposte. Questa condizione consente manipolazioni linguistiche ‘geometriche’ simili a quelle che avvengono in una rete convoluzionale di immagini, permettendoci di ottenere risultati che possono superare i metodi Bag-of-words standard (come Tf-Idf).
Per testare questo approccio, ho utilizzato il Twitter Sentiment Analysis Dataset (http://thinknook.com/wp-content/uploads/2012/09/Sentiment-Analysis-Dataset.zip), composto da circa 1.400.000 tweet etichettati. Il set di dati è piuttosto rumoroso e l’accuratezza di validazione complessiva di molti algoritmi standard è sempre di circa il 75%.
Per Word2Vec, ci sono alcuni scenari alternativi:
-
- Gensim (la scelta migliore nella maggior parte dei casi) – https://radimrehurek.com/gensim/index.html
- Implementazioni personalizzate basate su NCE (Noise Contrastive Estimation) o Hierarchical Softmax. Sono abbastanza facili da implementare con Tensorflow, ma richiedono uno sforzo supplementare, che spesso non è necessario.
- Uno strato di incorporazione iniziale. Questo approccio è il più semplice. Tuttavia, le prestazioni di addestramento sono peggiori perché la stessa rete deve imparare buone rappresentazioni di parole e, allo stesso tempo, ottimizzare i suoi pesi per minimizzare l’entropia incrociata in uscita.
Preferisco addestrare un modello Gensim Word2Vec con una dimensione del vettore pari a 512 e una finestra di 10 token. Il set di allenamento è composto da 1.000.000 di tweet e il set di test da 100.000 tweet. Entrambi gli insiemi vengono mescolati prima di tutte le epoche. Poiché la lunghezza media di un tweet è di circa 11 token (con un massimo di 53), ho deciso di fissare la lunghezza massima a 15 token (naturalmente, questo valore può essere aumentato, ma per la maggior parte dei tweet, l’input della rete convoluzionale sarà imbottito con molti vettori vuoti).
Nella figura seguente, c’è una rappresentazione schematica del processo, partendo dall’incorporazione della parola e continuando con alcune convoluzioni 1D:
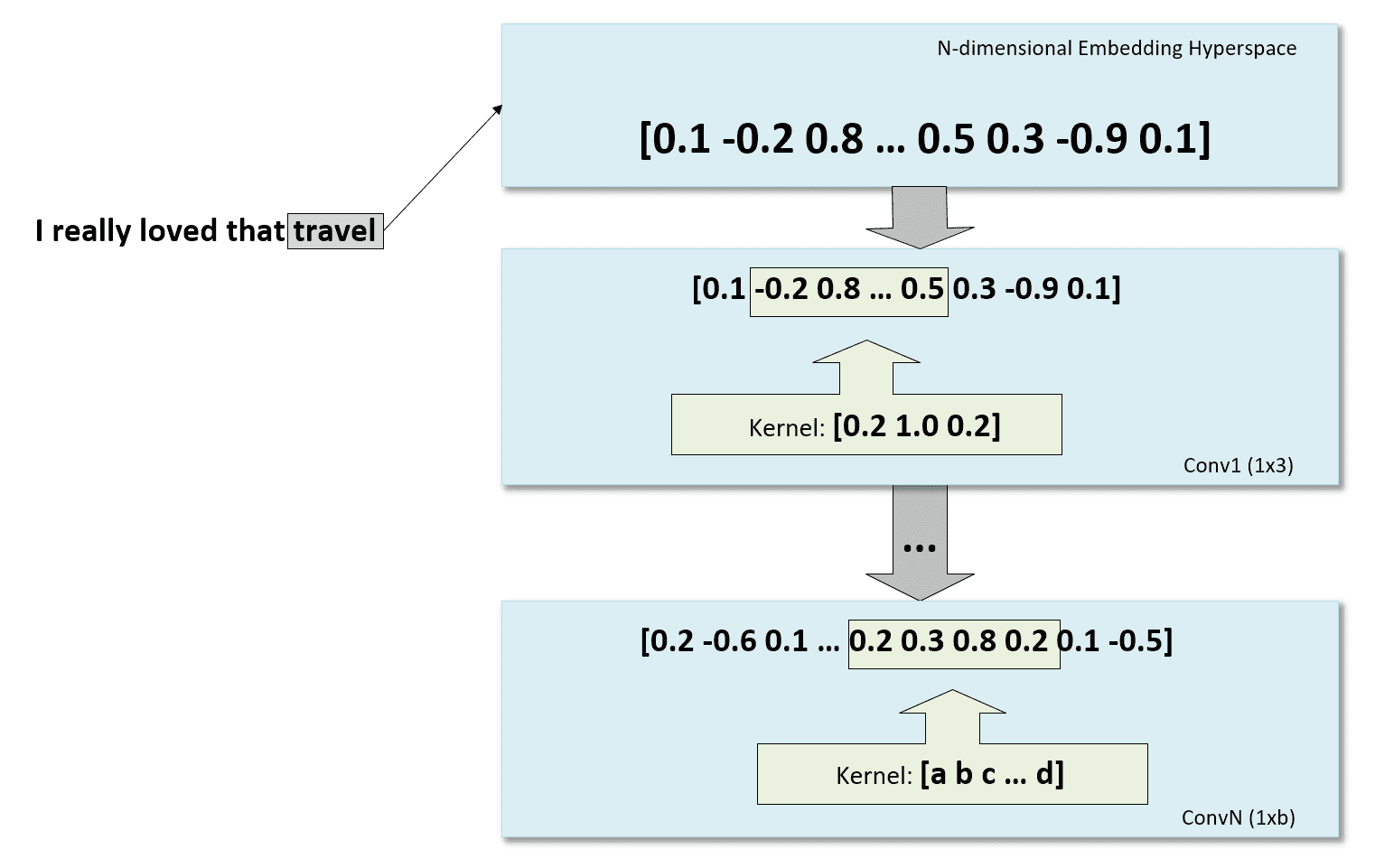
Il codice completo (copiato in questo GIST e disponibile anche nel repository: https://github.com/giuseppebonaccorso/twitter_sentiment_analysis_word2vec_convnet) è:
import keras.backend as K
import multiprocessing
import tensorflow as tf
from gensim.models.word2vec import Word2Vec
from keras.callbacks import EarlyStopping
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Flatten
from keras.layers.convolutional import Conv1D
from keras.optimizers import Adam
from nltk.stem.lancaster import LancasterStemmer
from nltk.tokenize import RegexpTokenizer
# Set random seed (for reproducibility)
np.random.seed(1000)
# Select whether using Keras with or without GPU support
# See: https://stackoverflow.com/questions/40690598/can-keras-with-tensorflow-backend-be-forced-to-use-cpu-or-gpu-at-will
use_gpu = True
config = tf.ConfigProto(intra_op_parallelism_threads=multiprocessing.cpu_count(),
inter_op_parallelism_threads=multiprocessing.cpu_count(),
allow_soft_placement=True,
device_count = {'CPU' : 1,
'GPU' : 1 if use_gpu else 0})
session = tf.Session(config=config)
K.set_session(session)
dataset_location = '/twitter/dataset.csv'
model_location = '/twitter/model/'
corpus = []
labels = []
# Parse tweets and sentiments
with open(dataset_location, 'r', encoding='utf-8') as df:
for i, line in enumerate(df):
if i == 0:
# Skip the header
continue
parts = line.strip().split(',')
# Sentiment (0 = Negative, 1 = Positive)
labels.append(int(parts[1].strip()))
# Tweet
tweet = parts[3].strip()
if tweet.startswith('"'):
tweet = tweet[1:]
if tweet.endswith('"'):
tweet = tweet[::-1]
corpus.append(tweet.strip().lower())
print('Corpus size: {}'.format(len(corpus)))
# Tokenize and stem
tkr = RegexpTokenizer('[a-zA-Z0-9@]+')
stemmer = LancasterStemmer()
tokenized_corpus = []
for i, tweet in enumerate(corpus):
tokens = [stemmer.stem(t) for t in tkr.tokenize(tweet) if not t.startswith('@')]
tokenized_corpus.append(tokens)
# Gensim Word2Vec model
vector_size = 512
window_size = 10
# Create Word2Vec
word2vec = Word2Vec(sentences=tokenized_corpus,
size=vector_size,
window=window_size,
negative=20,
iter=50,
seed=1000,
workers=multiprocessing.cpu_count())
# Copy word vectors and delete Word2Vec model and original corpus to save memory
X_vecs = word2vec.wv
del word2vec
del corpus
# Train subset size (0 < size < len(tokenized_corpus))
train_size = 1000000
# Test subset size (0 < size < len(tokenized_corpus) - train_size)
test_size = 100000
# Compute average and max tweet length
avg_length = 0.0
max_length = 0
for tweet in tokenized_corpus:
if len(tweet) > max_length:
max_length = len(tweet)
avg_length += float(len(tweet))
print('Average tweet length: {}'.format(avg_length / float(len(tokenized_corpus))))
print('Max tweet length: {}'.format(max_length))
# Tweet max length (number of tokens)
max_tweet_length = 15
# Create train and test sets
# Generate random indexes
indexes = set(np.random.choice(len(tokenized_corpus), train_size + test_size, replace=False))
X_train = np.zeros((train_size, max_tweet_length, vector_size), dtype=K.floatx())
Y_train = np.zeros((train_size, 2), dtype=np.int32)
X_test = np.zeros((test_size, max_tweet_length, vector_size), dtype=K.floatx())
Y_test = np.zeros((test_size, 2), dtype=np.int32)
for i, index in enumerate(indexes):
for t, token in enumerate(tokenized_corpus[index]):
if t >= max_tweet_length:
break
if token not in X_vecs:
continue
if i < train_size:
X_train[i, t, :] = X_vecs[token]
else:
X_test[i - train_size, t, :] = X_vecs[token]
if i < train_size:
Y_train[i, :] = [1.0, 0.0] if labels[index] == 0 else [0.0, 1.0]
else:
Y_test[i - train_size, :] = [1.0, 0.0] if labels[index] == 0 else [0.0, 1.0]
# Keras convolutional model
batch_size = 32
nb_epochs = 100
model = Sequential()
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same', input_shape=(max_tweet_length, vector_size)))
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=3, activation='elu', padding='same'))
model.add(Dropout(0.25))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Conv1D(32, kernel_size=2, activation='elu', padding='same'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='tanh'))
model.add(Dense(256, activation='tanh'))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])
# Fit the model
model.fit(X_train, Y_train,
batch_size=batch_size,
shuffle=True,
epochs=nb_epochs,
validation_data=(X_test, Y_test),
callbacks=[EarlyStopping(min_delta=0.00025, patience=2)])
1000000/1000000 [==============================] - 240s - loss: 0.5171 - acc: 0.7492 - val_loss: 0.4769 - val_acc: 0.7748 Epoch 2/100 1000000/1000000 [==============================] - 213s - loss: 0.4922 - acc: 0.7643 - val_loss: 0.4640 - val_acc: 0.7814 Epoch 3/100 1000000/1000000 [==============================] - 230s - loss: 0.4801 - acc: 0.7710 - val_loss: 0.4581 - val_acc: 0.7839 Epoch 4/100 1000000/1000000 [==============================] - 197s - loss: 0.4729 - acc: 0.7755 - val_loss: 0.4525 - val_acc: 0.7860 Epoch 5/100 1000000/1000000 [==============================] - 185s - loss: 0.4677 - acc: 0.7785 - val_loss: 0.4493 - val_acc: 0.7887 Epoch 6/100 1000000/1000000 [==============================] - 183s - loss: 0.4637 - acc: 0.7811 - val_loss: 0.4455 - val_acc: 0.7917 Epoch 7/100 1000000/1000000 [==============================] - 183s - loss: 0.4605 - acc: 0.7832 - val_loss: 0.4426 - val_acc: 0.7938 Epoch 8/100 1000000/1000000 [==============================] - 189s - loss: 0.4576 - acc: 0.7848 - val_loss: 0.4422 - val_acc: 0.7934 Epoch 9/100 1000000/1000000 [==============================] - 193s - loss: 0.4552 - acc: 0.7863 - val_loss: 0.4412 - val_acc: 0.7942 Epoch 10/100 1000000/1000000 [==============================] - 197s - loss: 0.4530 - acc: 0.7876 - val_loss: 0.4431 - val_acc: 0.7934 Epoch 11/100 1000000/1000000 [==============================] - 201s - loss: 0.4508 - acc: 0.7889 - val_loss: 0.4415 - val_acc: 0.7947 Epoch 12/100 1000000/1000000 [==============================] - 204s - loss: 0.4489 - acc: 0.7902 - val_loss: 0.4415 - val_acc: 0.7938
L’addestramento è stato interrotto dal callback Early Stopping dopo la dodicesima iterazione, quando l’accuratezza di validazione era di circa il 79,4%, con una perdita di validazione di 0,44.
I possibili miglioramenti o esperimenti che proverò sono:
-
- Dimensioni diverse del vettore di parole (ho già provato con 128 e 256, ma vorrei risparmiare più memoria)
- Strato incorporato
- Pooling medio o massimo per ridurre la dimensionalità
- Architetture diverse
Il modello precedente è stato addestrato su una GTX 1080 in circa 40 minuti.
Se ti piace l’articolo, puoi sempre fare una donazione per supportare la mia attività. Basta un caffè!