
Il filtraggio collaborativo senza modello è un approccio “leggero” ai sistemi di raccomandazione. Si basa sempre sulla “collaborazione” implicita (per quanto riguarda le valutazioni) tra gli utenti. Tuttavia, viene calcolato in memoria senza utilizzare algoritmi complessi come ALS (Alternating Least Squares) che possono essere eseguiti in un ambiente parallelo (come Spark).
Se ipotizziamo di avere N utenti e M prodotti, è possibile definire una matrice rada di preferenze degli utenti:
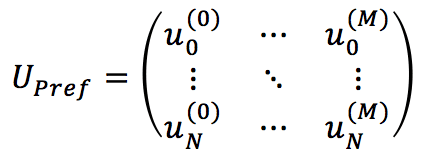
Ogni elemento rappresenta la valutazione dell’utente sull’articolo j (0 significa che non è stata fornita alcuna valutazione). Per affrontare le differenze appartenenti a molti contesti diversi, è utile definire due tipi di valutazioni (o feedback):
-
- Feedback esplicito: una valutazione effettiva (come tre stelle o 8 su 10).
- Feedback implicito: visualizzazione di una pagina, riproduzione di una canzone, riproduzione di un movimento e così via.
I diversi tipi di feedback determinano anche la metrica migliore per confrontare gli utenti. Una volta popolata la matrice delle preferenze dell’utente, è necessario calcolare la matrice di affinità basata su una metrica di somiglianza (la più comune è quella euclidea):
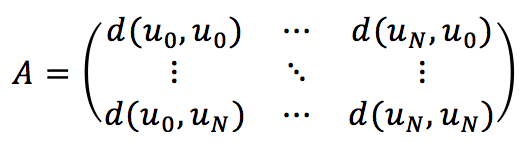
Questa matrice viene costruita considerando le righe di Upref. In particolare, Upref[i] rappresenta il vettore di preferenze (prodotti complessivi) per l’utente i.
Quando il feedback è esplicito, può essere utile continuare a usare la metrica euclidea, ma quando è implicito, può avere un significato diverso e può essere meglio scegliere un’altra funzione metrica. Ad esempio, se utilizziamo una codifica binaria per il feedback (0 significa nessuna interazione e una interazione singola o multipla), potremmo essere interessati a considerare due utenti simili quando hanno la stessa quantità di interazioni (visualizzazioni di pagine, riproduzioni di canzoni/film, …). Pertanto, la distanza di Hamming può essere più appropriata.
In questa implementazione, ho utilizzato Scikit-Learn per calcolare le distanze a coppie, ma altre soluzioni interessanti come Crab (http://muricoca.github.io/crab/). Il codice sorgente è disponibile anche in questo GIST.
from scipy.sparse import dok_matrix
from sklearn.metrics.pairwise import pairwise_distances
import numpy as np
# Set random seed (for reproducibility)
np.random.seed(1000)
# Create a dummy user-item dataset
nb_users = 1000
nb_products = 2500
max_rating = 5
max_rated_products = 500
X_preferences = dok_matrix((nb_users, nb_products), dtype=np.uint8)
for i in range(nb_users):
# Extract n random products
n_products = np.random.randint(0, max_rated_products+1)
products = np.random.randint(0, nb_products, size=n_products)
# Populate preference sparse matrix
for p in products:
X_preferences[i, p] = np.random.randint(0, max_rating+1)
# Compute pairwise distances
distance_matrix = pairwise_distances(X_preferences, metric='euclidean')
# Sort distances
sorted_distances = np.argsort(distance_matrix, axis=1)
test_user=500
# Take the top-10 simular users
for d in sorted_distances[test_user][::-1][0:10]:
print(d)
630 189 781 199 789 697 689 105 889 893
Una volta determinato l’elenco dei migliori vicini, è possibile suggerire i prodotti top-k, selezionandoli dall’unione dei prodotti “vicini” più votati:
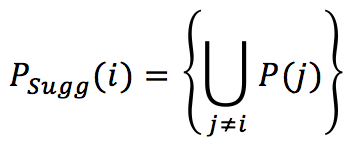
La valutazione prevista per un elemento suggerito può essere ottenuta come media ponderata del vicinato. Ad esempio, è possibile determinare un vettore di pesatura utilizzando una funzione softmax:
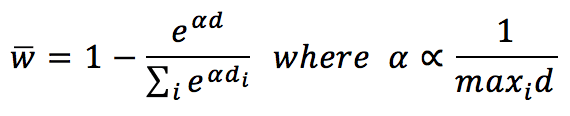
Alpha è un parametro di normalizzazione introdotto per evitare un overflow con distanze troppo grandi. Il vettore peso si riferisce al sottoinsieme di articoli suggeriti. La valutazione media si ottiene come segue:
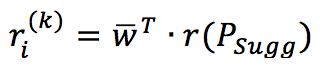
Naturalmente, questo è possibile solo quando il lettore può impiegare diverse tecniche per calcolare il rating atteso. Ad esempio, è possibile utilizzare una funzione di base radiale con una bassa varianza per penalizzare i contributi forniti dagli elementi più distanti. Allo stesso tempo, è possibile implementare diverse affinità per lo stesso compito, valutando la differenza nei prodotti suggeriti. Un recommender non è raramente basato su una soluzione “off-the-shelf”, a causa delle diversità intrinseche in diversi contesti aziendali. Pertanto, suggerisco sempre di provare varie alternative prima di prendere la decisione finale.
Se ti piace l’articolo, puoi sempre fare una donazione per supportare la mia attività. Basta un caffè!