
Molti algoritmi di clustering devono definire il numero di cluster desiderati prima di adattare il modello. Questo requisito può apparire come una contraddizione in uno scenario non supervisionato. Tuttavia, negli scenari reali, la scienza dei dati spesso conosce già una gamma ragionevole di cluster. Purtroppo, questo non implica la possibilità di definire il numero ottimale di cluster senza ulteriori analisi.
L’analisi dell’instabilità dei cluster è uno strumento potente per valutare l’ottimalità di un algoritmo o di una configurazione specifica. L’idea, sviluppata in [1], è semplice e può essere facilmente compresa utilizzando un’analogia meccanica. Se abbiamo delle palline su un tavolo, vogliamo raggrupparle in modo che piccole perturbazioni (movimenti) non possano alterare l’assegnazione iniziale del cluster. Per esempio, se due gruppi sono molto vicini, una perturbazione può spingere una sfera in un altro cluster, come mostrato nella figura seguente:
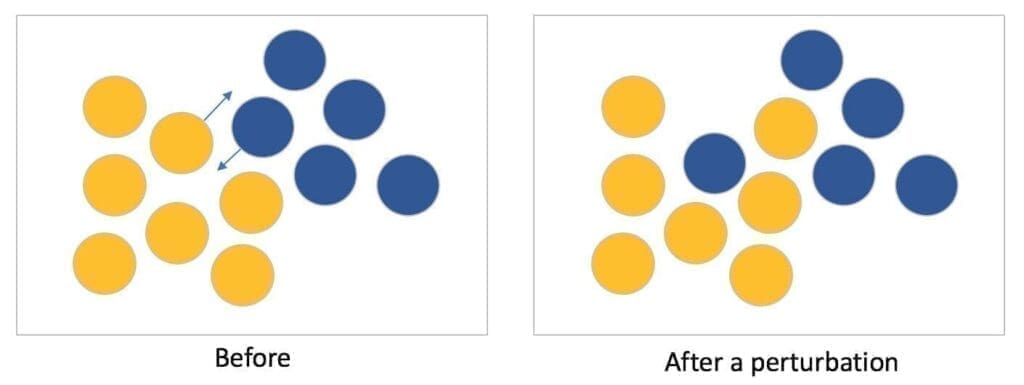
Più formalmente, se consideriamo una funzione di clustering C(X) e un set di dati originale X, possiamo creare n versioni perturbate di X (ad esempio, aggiungendo rumore o sottocampionamento):
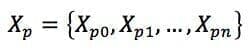
Considerando una funzione metrica di distanza d(X, Y) tra due raggruppamenti (Euclidea, Hamming e così via), è possibile definire l’instabilità come:
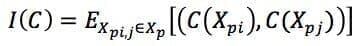
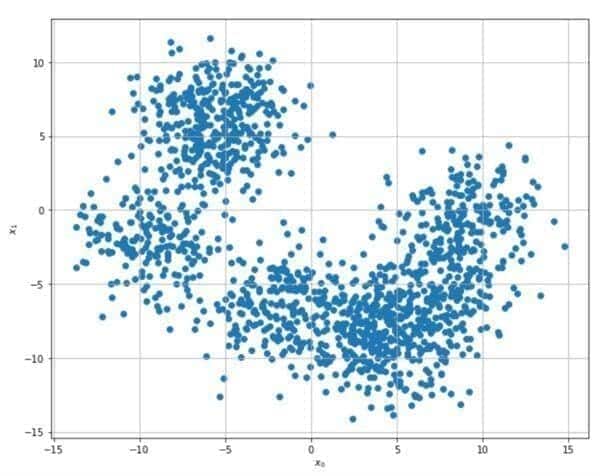
Il seguente esempio si basa sull’algoritmo Scikit-Learn e K-Means. Il set di dati originale (generato utilizzando la funzione make_blobs) è mostrato nella figura seguente:
Per verificare la stabilità, vengono generate 20 versioni rumorose e il processo viene ripetuto per un numero di cluster compreso tra 2 e 15, utilizzando la distanza di Hamming normalizzata:
Il grafico corrispondente è:
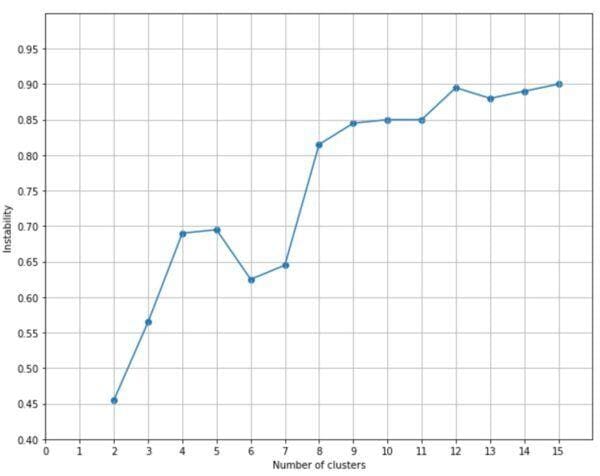
Se escludiamo i cluster 2 e 3, una buona soluzione sembra essere offerta da n=6, dove l’instabilità ha un minimo locale. Valori maggiori non sono accettabili perché l’instabilità aumenta oltre una soglia accettabile. Dopotutto, considerando la distribuzione iniziale, è facile capire che molti cluster (ad esempio, 15) conducono a gruppi molto vicini, dove una perturbazione può alterare drasticamente la configurazione, spingendo troppi punti in un cluster diverso.
Scegliendo n=6, un K-Means predefinito di Scikit-Learn produce il seguente risultato:
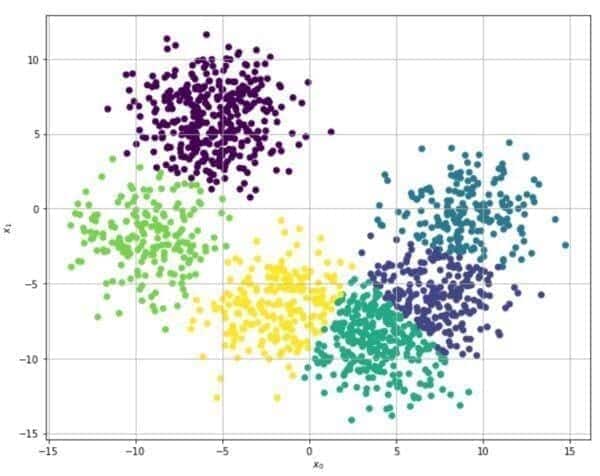
Il raggruppamento appare ragionevole e i blocchi mostrano una buona coesione interna, anche se la separazione inter-cluster non è molto elevata (a causa della distribuzione originale, che è piuttosto densa).
Riferimenti:
-
- Von Luxburg U., Stabilità dei cluster: una panoramica, arXiv 1007:1075v1
Se ti piace l’articolo, puoi sempre fare una donazione per supportare la mia attività. Basta un caffè!