
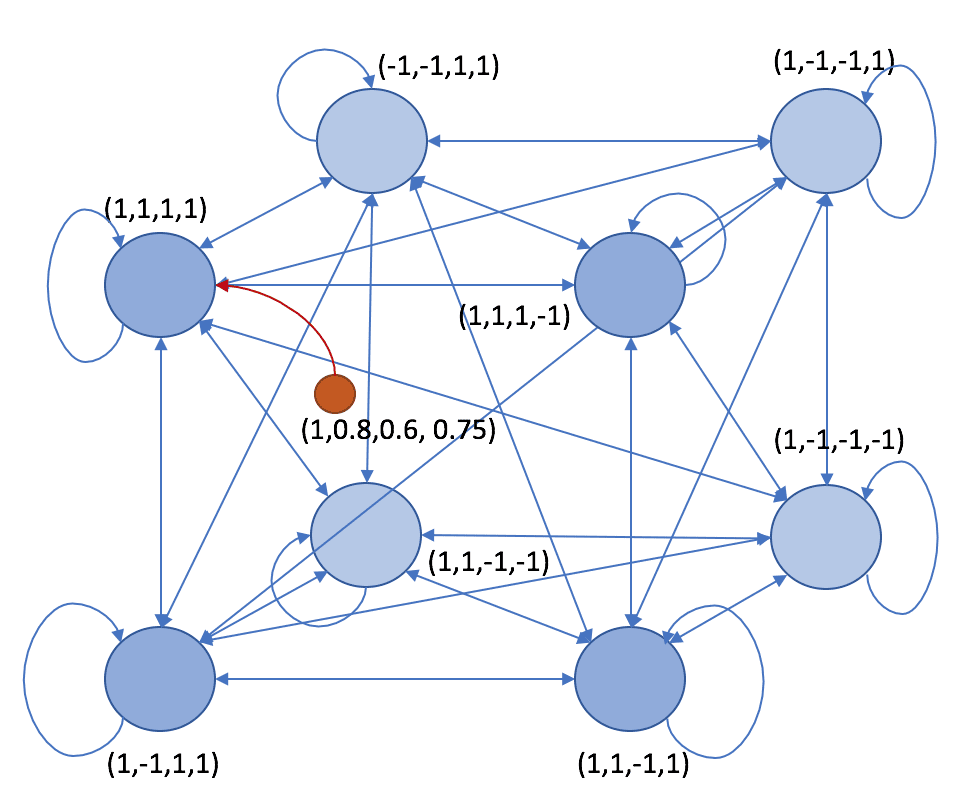
Il Brain-State-in-a-Box è un modello neurale proposto da Anderson, Silverstein, Ritz e Jones nel 1977, che presenta analogie molto forti con le reti di Hopfield (leggere il post precedente su di esse). La struttura della rete è simile: ricorrente, completamente connessa con pesi simmetrici e connessioni auto-ricorrenti non nulle. Tutti i neuroni sono bipolari (-1 e 1). Se ci sono N neuroni, è possibile immaginare un ipercubo a N dimensioni:
La differenza principale con una rete Hopfield è la funzione di attivazione:
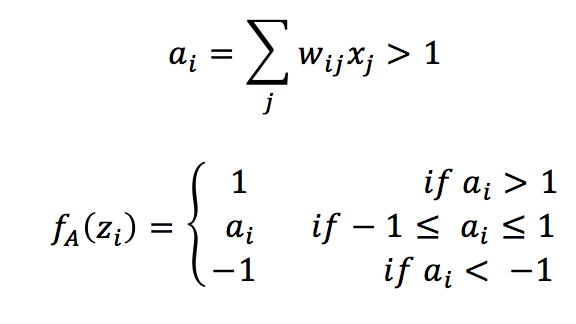
E la dinamica che, in questo caso, è sincrona. Pertanto, tutti i neuroni vengono aggiornati contemporaneamente.
La funzione di attivazione è lineare quando l’ingresso ponderato a(i) è delimitato tra -1 e 1 e satura a -1 e 1 al di fuori dei confini. Uno stato stabile della rete è uno dei vertici dell’ipercubo (ecco perché si chiama così). La regola di addestramento è sempre una Hebbian estesa basata sull’input grezzo pre-sinaptico e post-sinaptico:
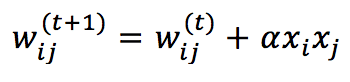
Dove α è il tasso di apprendimento.
La procedura di apprendimento è analoga a quella impiegata per le reti di Hopfield (iterazione degli aggiornamenti dei pesi fino alla convergenza), mentre il recupero di un modello a partire da uno corrotto viene ora ‘filtrato’ dalla funzione di attivazione satura. Quando viene presentato un modello rumoroso, vengono calcolate tutte le attivazioni e la procedura viene ripetuta finché la rete non converge verso uno stato stabile.
L’esempio si basa sulle reti di Hopfield ed è disponibile su questo GIST:
import matplotlib.pyplot as plt
import numpy as np
# Set random seed for reproducibility
np.random.seed(1000)
nb_patterns = 4
pattern_width = 4
pattern_height = 4
max_iterations = 100
learning_rate = 0.5
# Initialize the patterns
X = np.zeros((nb_patterns, pattern_width * pattern_height))
X[0] = [-1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1]
X[1] = [-1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, 1, -1, -1, -1, -1]
X[2] = [-1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, 1, 1, -1, -1]
X[3] = [1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, -1, -1, 1, 1]
# Show the patterns
fig, ax = plt.subplots(1, nb_patterns, figsize=(10, 5))
for i in range(nb_patterns):
ax[i].matshow(X[i].reshape((pattern_height, pattern_width)), cmap='gray')
ax[i].set_xticks([])
ax[i].set_yticks([])
plt.show()
# Initialize the weight matrix
W = np.random.uniform(-0.1, 0.1, size=(pattern_width * pattern_height, pattern_width * pattern_height))
W = W + W.T
# Create a vectorized activation function
def activation(x):
if x > 1.0:
return 1.0
elif x < -1.0:
return -1.0
else:
return x
act = np.vectorize(activation)
# Train the network
for _ in range(max_iterations):
for n in range(nb_patterns):
for i in range(pattern_width * pattern_height):
for j in range(pattern_width * pattern_height):
W[i, j] += learning_rate * X[n, i] * X[n, j]
W[j, i] = W[i, j]
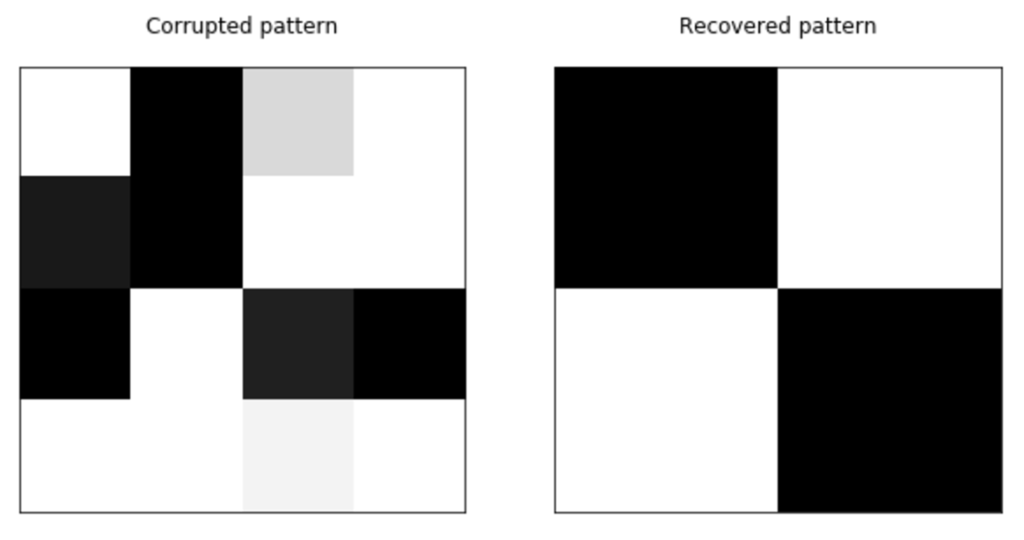
# Create a corrupted test pattern
x_test = np.array([1, -1, 0.7, 1, -0.8, -1, 1, 1, -1, 1, -0.75, -1, 1, 1, 0.9, 1])
# Recover the original patterns
A = x_test.copy()
for _ in range(max_iterations):
for i in range(pattern_width * pattern_height):
A[i] = activation(np.dot(W[i], A))
# Show corrupted and recovered patterns
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].matshow(x_test.reshape(pattern_height, pattern_width), cmap='gray')
ax[0].set_title('Corrupted pattern')
ax[0].set_xticks([])
ax[0].set_yticks([])
ax[1].matshow(A.reshape(pattern_height, pattern_width), cmap='gray')
ax[1].set_title('Recovered pattern')
ax[1].set_xticks([])
ax[1].set_yticks([])
plt.show()
Tuttavia, in questo caso, abbiamo creato un modello che si trova “all’interno” del riquadro, perché alcuni dei valori sono compresi tra -1 e 1:
Per ulteriori informazioni, le suggerisco:
-
- Hertz J.A, Krogh A.S., Palmer R.G, Introduction To The Theory Of Neural Computation, Santa Fe Institute Series
Se ti piace l’articolo, puoi sempre fare una donazione per supportare la mia attività. Basta un caffè!