
Pensa a una passeggiata lungo una spiaggia. La radio di un piccolo chiosco bar viene accesa e un DJ locale annuncia una canzone degli anni ’80. Immediatamente, ti viene in mente l’immagine di un’automobile. È la tua prima auto, una spider blu di seconda mano. Mentre ascoltavi la stessa canzone, hai accompagnato la tua ragazza in spiaggia circa 25 anni fa. È stata la prima volta che hai fatto l’amore con lei. Ora immagina un piccolo animale (normalmente una preda, come un roditore) che si aggira nella foresta e cerca cibo. All’improvviso si sente un suono e il roditore alza la testa. È lo scroscio dell’acqua o il ruggito di un leone? Possiamo saltare la risposta in questo momento. Pensiamo solo ai modi in cui può funzionare la memoria di un animale.
L’informatica ci ha fatto pensare che i ricordi debbano essere sempre senza perdite, efficienti e organizzati come archivi strutturati. Possono essere suddivisi in slot di dimensioni standard e ogni elemento può essere memorizzato in uno o più slot. Una volta fatto, è sufficiente salvare due riferimenti: un puntatore (un numero posizionale, una coppia di coordinate o qualsiasi altro elemento) e il numero di slot. Ad esempio, il libro “Guerra e Pace” (supponiamo che la sua lunghezza sia di 1000 unità) può essere memorizzato in una memoria nella posizione 684, quindi la coppia di riferimento è (684, 1000). Se necessario, è sufficiente recuperare 1000 unità a partire dalla posizione 684, e ogni singola, esatta parola scritta da Tolstoj apparirà davanti ai suoi occhi.
Una RAM(Random Access Memory) funziona in questo modo (così come gli Hard Disk e altri supporti simili). Si tratta di una strategia di archiviazione efficiente? Naturalmente lo è, e ogni programmatore sa come lavorare con questo tipo di memoria. Una variabile ha un tipo (che determina anche la sua dimensione). Un array ha un tipo e una struttura dimensionale. In entrambi i casi, è possibile accedere a ogni elemento a una velocità molto elevata utilizzando nomi e indici.
Ora pensiamo di nuovo alla piccola preda. La sua memoria è strutturata in questo modo? Supponiamo che lo sia. Il processo può essere descritto con le seguenti fasi: il suono viene prodotto e le onde di pressione si propagano a circa 330 m/s e arrivano alle orecchie. Un meccanismo complesso trasforma il suono in un segnale elettrico inviato al cervello, dove una serie di trasformazioni dovrebbe guidare il riconoscimento. Se la memoria fosse strutturata come una libreria, si dovrebbe eseguire un processo di scansione, confrontando ogni modello con quello nuovo. Bisogna trovare l’elemento più simile il prima possibile e scegliere l’azione conseguente. L’algoritmo del caso peggiore per una memoria con n locazioni ha questa struttura:
-
- Per ogni posizione di memoria i:
- Se Memoria[i] == Elemento:
- restituire l’elemento
- Altrimenti continua
- Se Memoria[i] == Elemento:
- Per ogni posizione di memoria i:
Il costo computazionale è O(n), che non è così male, ma richiede un numero massimo di n confronti. Una soluzione migliore si basa sul concetto di hash o firma (per ulteriori informazioni, consulti le funzioni hash). Ogni elemento è associato a un hash (unico), che può essere un numero intero utilizzato come indice per un array troppo completo (N >> n). Il costo computazionale di una buona funzione hash è costante O(1), così come la fase di recupero (perché l’hash è normalmente quasi unico). Tuttavia, sorge un altro problema. Una memoria simile alla RAM ha bisogno di posizioni esatte o di una scansione completa, ma invece di confronti diretti, è possibile utilizzare una misura di somiglianza (che introduce un po’ di fuzzy, consentendo di abbinare modelli rumorosi). Con una funzione hash, il costo computazionale si riduce drasticamente, ma la somiglianza diventa quasi impossibile, perché gli algoritmi sono studiati per generare hash completamente diversi, anche per cambiamenti molto piccoli nell’input.
In fin dei conti, questo tipo di memoria presenta troppi problemi e una domanda naturale è: come possono gli animali gestirli tutti? In effetti, i cervelli animali evitano completamente questi problemi. La loro memoria non è RAM e tutte le informazioni sono memorizzate in modo completamente diverso. Senza considerare tutte le distinzioni introdotte dagli psicologi cognitivi (memoria a breve termine, a lungo termine, di lavoro, e così via), possiamo dire che un modello di ingresso A, dopo alcune fasi di elaborazione, viene trasformato in un altro modello B:
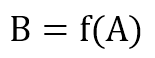
Normalmente, B ha le stesse capacità di uno stimolo originale. Ciò significa che un ruggito correttamente riconosciuto suscita la stessa risposta della vista di un leone reale, consentendo una sorta di previsione o di anticipazione dell’azione. Inoltre, se A è parzialmente corrotto rispetto alla versione originale (in questo caso, ipotizziamo un rumore gaussiano), la funzione è in grado di denoising il suo output:
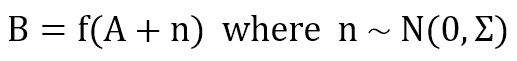
Questo approccio è chiamato associativo ed è stato studiato da diversi ricercatori (come [1] e [2]) nei campi dell’informatica e delle neuroscienze computazionali. Sono stati ideati e progettati molti modelli (a volte completamente diversi nella loro formulazione matematica) (come BAM, SOM e Reti Hopfield). Tuttavia, la loro logica interna è sempre la stessa: un insieme di modelli simili (in termini di caratteristiche a grana grossa/fine) deve suscitare una risposta simile, e il tempo di inferenza deve essere il più breve possibile. Se vuole capire brevemente come funzionano alcuni di questi modelli, può consultare questi articoli precedenti:
Per riassumere questa idea, può considerare la figura seguente:
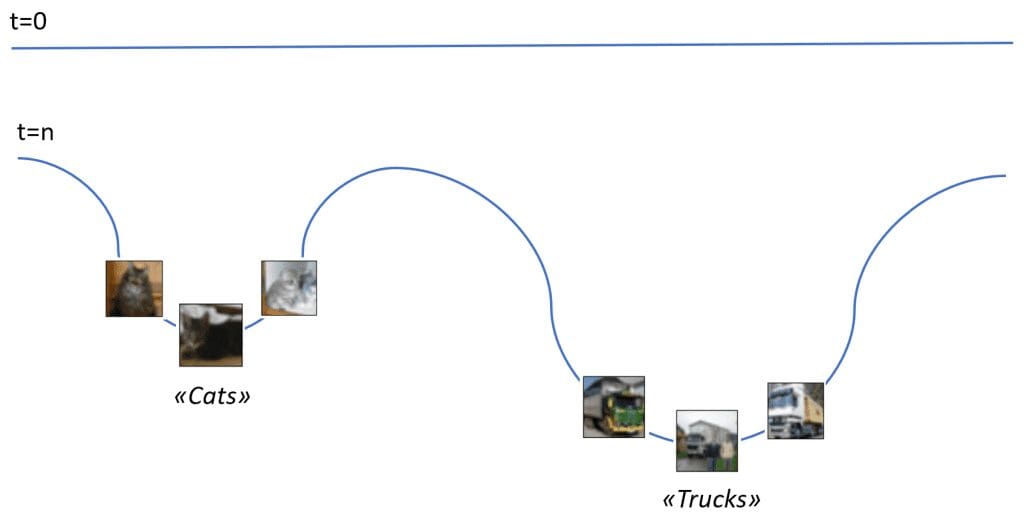
La linea blu è la rappresentazione di una superficie di memoria. Al momento t=0, non è stato immagazzinato nulla e la linea è diritta. Dopo un po’ di esperienza, appaiono due bacini. Con una certa fantasia, se l’immagine di un nuovo gatto viene inviata vicino al bacino, scenderà fino a raggiungere il punto minimo, dove viene memorizzato il concetto di “gatto”. Lo stesso accade per la categoria dei “camion” e così via per qualsiasi altro elemento semantico associato a una percezione specifica. Anche se questo approccio si basa sul concetto di energia e necessita di un’evoluzione dinamica, può essere impiegato in modo elegante per spiegare la differenza tra accesso casuale e accesso associato. Allo stesso tempo, è possibile recuperare una famiglia di modelli e le loro caratteristiche comuni partendo da un bacino (che è un minimo nella superficie di memoria). Immanuel Kant l’ha definita sintesi figurata e rappresenta uno dei risultati più brillanti che la neocorteccia consente.
In effetti, non verranno recuperate immagini specifiche se si chiede a una persona di pensare a un gatto (supponendo che questo concetto non sia troppo familiare). Al contrario, una rappresentazione generica, basata sulle caratteristiche, viene evocata e adattata a qualsiasi possibile istanza appartenente alla stessa famiglia. Per esprimere questo concetto in modo più conciso, possiamo dire che possiamo recuperare interi concetti attraverso la raccolta di caratteristiche comuni e, se necessario, possiamo abbinare queste caratteristiche a un’istanza reale.
Per esempio, alcuni cani non sono molto dissimili da alcuni gatti, ed è naturale chiedersi: è un cane o un gatto? In questo caso, l’insieme di caratteristiche ha una sovrapposizione parziale e dobbiamo raccogliere ulteriori informazioni per raggiungere una decisione finale. Allo stesso tempo, se un gatto è nascosto dietro una tenda e qualcuno invita un amico a immaginarlo, tutte le possibili caratteristiche del concetto di “gatto” saranno recuperate per permettere di indovinare il colore, la razza e così via. Provate voi stessi. Forse l’amico sa che sono preferiti gli animali soffici, quindi è spinto a creare il modello in persiano. Tuttavia, dopo qualche secondo, un insieme di attributi è pronto per essere comunicato.
Sorprendentemente, quando la tenda viene aperta, appare un coniglietto bianco. In questo caso, il processo è un po’ più complesso perché la persona si è fidata del suo amico e ha implicitamente assegnato un’alta priorità a tutte le informazioni (anche quelle raccolte in precedenza). Per quanto riguarda la probabilità, diciamo che la distribuzione preventiva ha raggiunto il picco intorno al concetto di “gatto”, evitando caratteristiche spurie che corrompono il modello mentale. (Nell’esempio precedente, probabilmente c’erano due picchi più piccoli intorno al concetto di “gatto” e “cane”, quindi il modello potrebbe essere parzialmente rumoroso, consentendo una maggiore libertà di scelta).
Quando appare l’immagine, quasi nessuna delle principali caratteristiche previste corrisponde al coniglietto, spingendo il cervello a resettare la sua convinzione (non immediatamente, perché il precedente mantiene un dubbio minimo). Fortunatamente, questa persona ha visto molti conigli prima di quel momento, e anche dopo tutte le indicazioni sbagliate, le sue memorie associative possono recuperare rapidamente un nuovo concetto, permettendo la decisione finale che l’animale non è un gatto. Un disco rigido doveva andare avanti e indietro molte volte, rallentando il processo in modo drammatico.
Un approccio diverso basato sugli eterocodificatori
Un etero-encoder è strutturalmente identico a un auto-encoder. L’unica differenza è l’associazione: quest’ultima addestra un modello per ottenere:
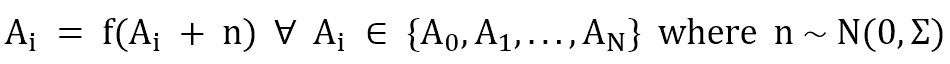
Mentre un etero-encoder addestra un modello che è in grado di eseguire l’associazione:
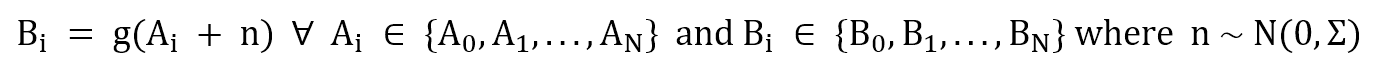
Il codice sorgente è riportato in questo GIST e alla fine dell’articolo. Si basa su Tensorflow (Python 3.5) e si divide in una parte di codifica, una piccola rete convoluzionale seguita da un livello denso. Trasforma l’ingresso (dimensione del lotto × 32 × 32 × 3) in un vettore di caratteristiche che può essere inserito nel decodificatore. Questo elabora il vettore di caratteristiche con un paio di strati densi ed esegue una deconvoluzione (convoluzione di trasposizione) per costruire l’uscita (dimensione del lotto × 32 × 32 × 3).
Il modello viene addestrato utilizzando una funzione di perdita L2 calcolata sulla differenza tra l’output previsto e quello predetto. Si può aggiungere un’ulteriore perdita L1 al vettore di caratteristiche per aumentare la spazialità. Il processo di addestramento richiede alcuni minuti con il supporto della GPU e 500 epoche.
Il modello in sé non è complesso né si basa sulla scienza missilistica, ma alcune considerazioni sono utili per capire perché questo approccio è davvero importante:
-
- Il modello è implicitamente cumulativo. In altre parole, la funzione g(-) lavora con tutte le immagini in ingresso, trasformandole nell’uscita corrispondente.
- No, se le dichiarazioni sono presenti. Nella logica algoritmica comune, g(-) deve verificare l’immagine di ingresso e selezionare la trasformazione giusta. Al contrario, un modello neurale può fare questa scelta in modo implicito.
- Tutte le trasformazioni del modello sono memorizzate nel set di parametri, la cui plasticità consente una formazione continua.
- Una versione di ingresso rumorosa suscita una risposta con una perdita di L2 ridotta al minimo rispetto a quella originale. Aumentando la complessità sia del codificatore che del decodificatore, è possibile aumentare ulteriormente la robustezza del rumore. Questo è un concetto fondamentale, perché avere due percezioni identiche è quasi impossibile.
Nel nostro “esperimento”, il set di dati di destinazione è una versione rimescolata di quello originale. Pertanto, sono possibili diverse sequenze periodiche. Lo dimostrerò con una fantasia fittizia. Ogni sequenza ha una lunghezza fissa di 20 immagini (19 associazioni). La prima immagine è scelta liberamente, mentre tutte le altre sono generate con un processo a catena.
Mattoni di esperienza
Ho selezionato in modo casuale (con seme fisso) 50 immagini Cifar-10 (attraverso la funzione di caricamento del set di dati di Keras) come elementi costitutivi della memoria etero-associativa. Purtroppo, le categorie sono piuttosto strane (rane, struzzi, cervi, automobili, aerei, camion e adorabili gatti), ma permettono di ricreare con un po’ di fantasia il possibile contorno. Il collage di immagini è mostrato nella figura seguente:

La sequenza originale (X_source) viene poi rimescolata e trasformata in una sequenza di destinazione (X_dest). In questo modo, ogni immagine originale sarà sempre associata ad un’altra appartenente allo stesso gruppo e si potranno scoprire diverse sequenze periodiche.
Alcune “storie”
L’utente può ampliare il set di dati e sperimentare diverse combinazioni. In questo caso, con 50 campioni, ho scoperto alcune sequenze interessanti che ho chiamato “storie”.
Periodo = 2

John stava guardando una barca, mentre un camion rumoroso dietro di lui attirava la sua attenzione su un muro di cemento che si stava costruendo dietro di lui.
Periodo = 7

Mentre passeggiava in un negozio di animali, John vide una rana esotica e improvvisamente si ricordò che doveva comprare del cibo per il suo gatto. Il suo marchio preferito è Acme Corp. e ha visto il loro camion diverse volte. Nel frattempo, la rana gracchia e gira la testa verso un altro terrario. Il colore della sabbia e il paesaggio artificiale lo spingono a pensare a un ranch dove ha cavalcato per la prima volta. Mentre trotterellava vicino a uno stagno, un’anatra ha attirato la sua attenzione e stava per cadere. La rana gracidò di nuovo in quel momento e lui decise di affrettarsi.
Periodo = 7

John osserva un piccolo uccello ricordando suo nonno, un appassionato osservatore di uccelli. Aveva una vecchia auto blu chiaro e, quando John era bambino, vide uno struzzo durante un breve viaggio con suo nonno. Il loro cagnolino ha iniziato ad abbaiare e ha chiesto al nonno di accelerare, ma lui ha risposto: “Ehi, questa non è una Ferrari!”. (Ok, la mia fantasia sta andando troppo veloce…). Durante lo stesso viaggio, hanno visto un cervo e John ha scattato una foto con la sua macchina fotografica nuova di zecca.
Periodo = 20 (due piani parzialmente sovrapposti)
Storia A:

Storia B:

Questi due casi sono leggermente più complessi e preferisco non fantasticare. Il concetto è sempre lo stesso: un input spinge la rete a produrre un’associazione B (che può essere composta da elementi visivi, uditivi, olfattivi, …). B può suscitare una nuova risposta C e così via.
Due elementi sono interessanti e meritano un’indagine:
-
- Utilizzando una Rete Neurale Ricorrente (come una LSTM) per elaborare brevi sequenze con componenti diversi (come immagini e suoni).
- Aggiunta di un livello “subconscio” che può influenzare l’output secondo un processo parzialmente autonomo.
Codice sorgente
import matplotlib.pyplot as plt
import multiprocessing
import numpy as np
import tensorflow as tf
from keras.datasets import cifar10
# Set random seed (for reproducibility)
np.random.seed(1000)
tf.set_random_seed(1000)
width = 32
height = 32
batch_size = 10
nb_epochs = 500
code_length = 1024
use_gpu = True
# Load the dataset
(X_train, Y_train), (X_test, Y_test) = cifar10.load_data()
# Select 50 samples
X_source = X_train[0:50]
X_dest = X_source.copy()
np.random.shuffle(X_dest)
def encoder(encoder_input):
# Convolutional layer 1
conv1 = tf.layers.conv2d(inputs=encoder_input,
filters=32,
kernel_size=(3, 3),
kernel_initializer=tf.contrib.layers.xavier_initializer(),
activation=tf.nn.tanh)
# Convolutional output (flattened)
conv_output = tf.contrib.layers.flatten(conv1)
# Encoder Dense layer 1
d_layer_1 = tf.layers.dense(inputs=conv_output,
units=1024,
activation=tf.nn.tanh)
# Code layer
code_layer = tf.layers.dense(inputs=d_layer_1,
units=code_length,
activation=tf.nn.tanh)
return code_layer
def decoder(code_sequence, bs):
# Decoder Dense layer 1
d_layer_1 = tf.layers.dense(inputs=code_sequence,
units=1024,
activation=tf.nn.tanh)
# Code output layer
code_output = tf.layers.dense(inputs=d_layer_1,
units=(height - 2) * (width - 2) * 3,
activation=tf.nn.tanh)
# Deconvolution input
deconv_input = tf.reshape(code_output, (bs, height - 2, width - 2, 3))
# Deconvolution layer 1
deconv1 = tf.layers.conv2d_transpose(inputs=deconv_input,
filters=3,
kernel_size=(3, 3),
kernel_initializer=tf.contrib.layers.xavier_initializer(),
activation=tf.sigmoid)
# Output batch
output_batch = tf.cast(tf.reshape(deconv1, (bs, height, width, 3)) * 255.0, tf.uint8)
return deconv1, output_batch
def create_batch(t):
X = np.zeros((batch_size, height, width, 3), dtype=np.float32)
Y = np.zeros((batch_size, height, width, 3), dtype=np.float32)
if t < X_source.shape[0] - batch_size:
tmax = t + batch_size
else:
tmax = X_source.shape[0]
for k, image in enumerate(X_source[t:tmax]):
X[k, :, :, :] = image / 255.0
for k, image in enumerate(X_dest[t:tmax]):
Y[k, :, :, :] = image / 255.0
return X, Y
# Create a Tensorflow Graph
graph = tf.Graph()
with graph.as_default():
with tf.device('/cpu:0'):
# Global step
global_step = tf.Variable(0, trainable=False)
with tf.device('/gpu:0' if use_gpu else '/cpu:0'):
# Input batch
input_images = tf.placeholder(tf.float32, shape=(None, height, width, 3))
# Output batch
output_images = tf.placeholder(tf.float32, shape=(None, height, width, 3))
# Batch_size
t_batch_size = tf.placeholder(tf.int32, shape=())
# Encoder
code_layer = encoder(encoder_input=input_images)
# Decoder
deconv_output, output_batch = decoder(code_sequence=code_layer,
bs=t_batch_size)
# Reconstruction L2 loss
loss = tf.nn.l2_loss(output_images - deconv_output)
# Training operations
learning_rate = tf.train.exponential_decay(learning_rate=0.00025,
global_step=global_step,
decay_steps=int(X_source.shape[0] / (2 * batch_size)),
decay_rate=0.9,
staircase=True)
trainer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_step = trainer.minimize(loss)
def predict(X, bs=1):
feed_dict = {
input_images: X.reshape((1, height, width, 3)) / 255.0,
output_images: np.zeros((bs, height, width, 3), dtype=np.float32),
t_batch_size: bs
}
return session.run([output_batch], feed_dict=feed_dict)[0]
def story(t):
oimages = np.zeros(shape=(20, height, width, 3), dtype=np.uint8)
oimages[0, :, :, :] = X_source[t]
for i in range(1, 20):
oimages[i, :, :, :] = predict(oimages[i - 1])
fig, ax = plt.subplots(2, 10, figsize=(18, 4))
for i in range(2):
for j in range(10):
ax[i, j].get_xaxis().set_visible(False)
ax[i, j].get_yaxis().set_visible(False)
ax[i, j].imshow(oimages[(10 * i) + j])
plt.show()
if __name__ == '__main__':
# Create a Tensorflow Session
config = tf.ConfigProto(intra_op_parallelism_threads=multiprocessing.cpu_count(),
inter_op_parallelism_threads=multiprocessing.cpu_count(),
allow_soft_placement=True,
device_count={'CPU': 1,
'GPU': 1 if use_gpu else 0})
session = tf.InteractiveSession(graph=graph, config=config)
# Initialize all variables
tf.global_variables_initializer().run()
# Train the model
for e in range(nb_epochs):
total_loss = 0.0
for t in range(0, X_source.shape[0], batch_size):
X, Y = create_batch(t)
feed_dict = {
input_images: X,
output_images: Y,
t_batch_size: batch_size
}
_, t_loss = session.run([training_step, loss], feed_dict=feed_dict)
total_loss += t_loss
print('Epoch {} - Loss: {}'.
format(e + 1,
total_loss / float(X_train.shape[0])))
# Show some stories
story(0)
# story(1)
# story(9)
# ...
Riferimenti
-
- Kosko B., Bidirectional Associative Memory, IEEE Transactions on Systems, Man, and Cybernetics, v. 18/1, 1988
- Dayan P., Abbott L. F., Theoretical Neuroscience, The MIT Press
- Trappenberg T., Fundamentals of Computational Neuroscience, Oxford University Press
- Izhikevich E. M., Dynamical Systems in Neuroscience, The MIT Press
- Rieke F., Warland D., Ruyter Van Steveninck R., Bialek W., Spikes: Exploring the Neural Code, A Bradford Book
Se ti piace l’articolo, puoi sempre fare una donazione per supportare la mia attività. Basta un caffè!